作为全球最大的程序员问答社区之一,StackOverflow在技术界拥有极高的权威性和影响力。很多人习惯通过搜索引擎访问StackOverflow的海量问答资源,然而令人意外的是,StackOverflow在其robots.txt文件中设置了禁止所有爬虫抓取的规则。这一操作显得颇为反常,尤其是在内容丰富并依赖网络曝光率的平台中。本文将深入剖析StackOverflow此举的具体内容、背后的动机及其对SEO生态和网站运营的潜在影响。 首先,了解robots.txt的作用尤为重要。作为一种标准的网络协议,robots.txt文件位于网站根目录,用于告知搜索引擎和其他网络爬虫哪些页面可以抓取、哪些页面不允许访问。
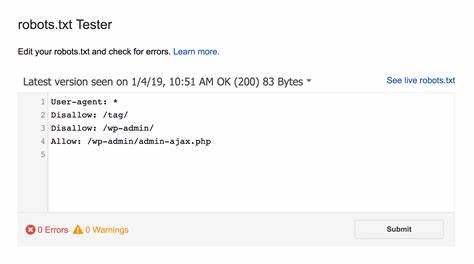
StackOverflow的robots.txt明确写道“User-agent: *”以及“Disallow: /”,意味着任何爬虫均被禁止抓取网站所有页面。此外,设置了“Content-signal: search=no, ai-train=no”的信号,进一步表明网站内容不允许被搜索或用于人工智能训练数据收集。 为何StackOverflow要采取如此严格的限制?通常,强烈限制爬虫可能会导致网站流量下降,影响内容的自然搜索排名。对此,一种可能的解释是保护知识产权和数据隐私。StackOverflow内包含大量用户原创的问答内容,禁止爬取意在防止第三方平台未经许可抓取并再利用这些数据,尤其是在AI模型训练日益普及的背景下,确保用户贡献的知识产权不被滥用。另外,这种做法还有助于缓解服务器压力,减少因频繁访问带来的资源消耗,尤其是在高峰时段,保证网站的稳定性和响应速度。
另一方面,此举对用户体验和搜索引擎的索引也带来了不利影响。禁止所有爬虫抓取意味着StackOverflow的内容无法被Google、百度等主流搜索引擎索引和展示,导致用户在搜索编程问题时可能不容易直接找到相关答案。由于StackOverflow一直以来都是程序员查找技术解决方案的重要来源,这种限制可能促使用户和开发者寻找替代平台,进而影响StackOverflow的长期用户黏性和社区活跃度。 从SEO角度来看,robots.txt的全面屏蔽是极为罕见的操作,尤其对于依赖高流量和高曝光率维持运营的网站。通常,网站会针对某些敏感页面设置禁止抓取规则,而非全站Block。StackOverflow此举可能反映出他们对数据安全和控制权的高度重视,同时也可能意味着他们已经通过其他渠道或技术优化了内容的分发和曝光,不再依赖传统搜索引擎流量。
此外,StackOverflow的禁爬设置还与当前人工智能数据训练相关政策趋势密切相关。面对众多AI公司无序采集在线内容,有些内容拥有者开始采取更加严格的版权保护措施。StackOverflow通过robots.txt明确告知AI训练机构该网站不允许使用其内容训练模型,有效防止知识产权被侵犯,保护社区贡献者的合法权益。这种做法或将为其他知识型社区树立新的范例,推动互联网内容的合理使用与授权。 然而,网站全面阻止爬虫也需要平衡开放性与安全性。长远来看,StackOverflow可能需要探索更灵活的策略,比如提供部分开放API接口,允许经过授权的合作伙伴合法访问数据,同时利用技术手段防止非法爬取。
通过智能授权机制,兼顾社区的活跃度、内容价值最大化以及版权保护,方能在保护与开放中寻找到最佳平衡点。 总结来说,StackOverflow禁止所有爬虫抓取体现了内容版权保护、服务稳定性及人工智能伦理等多重考量。虽然短期内可能影响其内容在搜索引擎上的可见度,但在数字版权日益重要的今天,这种严格限制有助于维护原创者的权益和社区生态的健康发展。对于网站运营者及SEO行业人士,StackOverflow的做法提醒我们在追求流量和排名时,不可忽视内容安全和合理授权的重要性。未来,随着数据使用规范的不断完善,互联网内容保护与开放的平衡将成为行业关注的焦点,而StackOverflow无疑为我们提供了值得思考的实践案例。