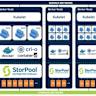
随着人工智能技术的蓬勃发展,从传统机器学习到深度学习再到生成式AI,AI工作负载的复杂度和计算需求持续激增。应对大规模、高性能以及多样化的AI任务,打造高效且灵活的软件栈已成为业界共识。近年来,Kubernetes、Ray、PyTorch与vLLM组合构建的开源AI计算栈逐渐成为主流选择,助力企业和开发者以稳定、高效且可扩展的方式应对AI计算挑战。本文将深入解读这一堆栈的架构层级、关键职责及其在实际场景中的典型应用,为关注AI基础设施和平台建设的读者提供专业视角。开源AI计算栈的价值和作用 AI计算密集型且数据量庞大,对计算资源的调度、管理和利用效率提出了极高要求。传统的单机或简单分布式方式已难以满足现代AI训练和推理的需求。
优秀的AI计算栈能够帮助团队实现大规模多任务并行,确保GPU等硬件资源的充分利用,同时提升开发效率,降低迭代成本。采用开源组件的方案还保证了生态的丰富性和技术的可持续发展。 Kubernetes作为容器编排的行业标准,提供了强大的集群管理、资源调度和多租户隔离能力;Ray作为分布式计算引擎,专注于细粒度任务调度和弹性扩展;PyTorch则是当今深度学习领域被广泛采用的框架,拥有卓越的灵活性和易用性;vLLM为基于变换器模型的推理引擎,针对大型语言模型推理进行了众多优化。 搭建完整AI计算栈架构 AI计算栈可以认知为包含三大层次,每层各司其职,共同协作完成从资源调度到深度学习训练与推理的全链路支持。第一层是训练与推理框架,主要负责模型定义、编译、自动微分以及运行时的性能优化。PyTorch作为目前最主流的深度学习框架,通过全自动微分和丰富的前沿模型库,满足AI开发者在训练复杂网络时的需求。
同时,针对大型语言模型的推理,vLLM优化了多GPU运行的效率与响应速度,支持持续批处理、分页注意力及猜测式解码等多种前沿技术,有效提升推理吞吐。 第二层为分布式计算引擎,代表技术是Ray。它能够将AI任务拆分成细粒度的子任务在集群中分配执行,负责任务调度、数据搬运、故障恢复和负载自动伸缩。Ray集成Python环境,自身支持GPU算力感知,极大便利了以Python为主的AI开发流程。此外,Ray的故障自动重试、弹性扩容机制确保任务高度可靠,即便在节点失效或资源波动情况下也能保障任务持续执行。 第三层则是容器编排器层,主流代表Kubernetes。
它主要负责集群资源的调配与多用户多租户的隔离管理,动态分配计算节点,调度整个作业并管理容器生命周期。Kubernetes提供丰富的资源配额、弹性扩缩容等机制,有效平衡多方资源竞争,提升基础设施利用率。Kubernetes的生态体系强大,配合云原生理念可实现与多云环境无缝对接。 实际应用:视频处理中的AI计算栈落地 视频内容审核作为一项复杂多样的AI任务,涉及视频解码、视觉与语音信号处理,再到复杂的语言模型推理。整个流程中,数据先由CPU完成视频解码和格式统一,随后多模态信息交由GPU执行计算机视觉和音频分析,最终由大型语言模型完成推理决策。 在这一场景中,PyTorch承载视觉和语音分类任务,保证模型高效运行。
vLLM处理多GPU环境下的自然语言推理任务。Ray负责将各个流程阶段拆分并调度到不同节点和容器,实现任务并行和高效资源利用。Kubernetes调配集群节点,保障容器运行环境稳定,处理多用户多任务隔离及资源调配。 通过这样分层分职责的设计,视频审核系统达到了高吞吐、低延迟与稳定性的平衡。 多领域领军企业的成功实践 Pinterest在其PinCompute AI平台中采用了Kubernetes + Ray + PyTorch + vLLM方案,极大提升了数据集迭代速度和模型训练效率。其训练作业GPU利用率超过90%,训练吞吐提升45%,同时成本下降近25%。
在批处理推理场景中,采用Ray与vLLM的结合实现了搜索质量推理任务成本降低30倍,吞吐提升4.5倍,作业运行时间缩短至原来的1/4,显著提升了处理能力和节省成本。 Uber凭借其Michelangelo平台,融合了Kubernetes对集群管理的强大支持,利用Ray的Python原生分布式能力管理大规模训练,并配合PyTorch深度学习框架和vLLM推理引擎不断优化大模型训练和推理流程。其大批量训练中,模型推理吞吐提升2到3倍,显著加快业务迭代节奏。同时,Uber借助Kubernetes实现了云上云下混合云的弹性调度,提升了整体平台效率。 Roblox的发展经历了多个阶段,从最早期的基于Kubeflow和Spark的数据处理转向引入Ray进行分布式训练和批量推理,最后逐渐将vLLM作为核心大型语言模型推理引擎,极大降低推理延迟和成本。其推理结构实现了十倍GPU利用率提升,以及对海量请求的高容错处理能力,确保了业务稳定运行。
针对后期训练的多样需求 后期训练工作流复杂,集合了在线推理与强化学习环节,涉及模型权重与数据流的频繁交互,呈现更高的分布式系统设计挑战。目前多种流行的开源后期训练框架均采用Ray作为调度引擎,PyTorch及DeepSpeed作为训练支撑,vLLM作为推理引擎,部署于Kubernetes或SLURM环境中。比如ByteDance的VeRL和NVIDIA的NeMo-RL均采用此堆栈组合,支持成千上万张GPU的规模化训练与推理,有效支撑RLHF(强化学习人类反馈)等复杂算法的高性能实现。 开源生态的未来发展趋势 AI计算栈中开源项目的融合日趋紧密,框架间相互协作不断完善,形成了强大的技术合力。Kubernetes和Ray正在共同推动容器级与任务级调度的协同优化,使得资源调度更智能、弹性更灵活。PyTorch持续拓展端到端深度学习功能,优化多GPU及分布式训练体验。
vLLM等推理引擎不断引入新技术,提升推理吞吐及降低延迟。未来,随着更大规模模型及多模态计算需求的爆发,这一堆栈有望引入更多深度集成及自动化能力,包括智能资源分配、动态任务迁移与多云无缝调度,进一步增强平台的敏捷性与成本效益。 总结 以Kubernetes为基础的容器管理,结合Ray的分布式任务调度,PyTorch的深度学习训练框架,以及vLLM的高效大语言模型推理引擎,构建了目前最受欢迎且成熟的开源AI计算栈。该堆栈以明确分工的三层架构支撑起AI从模型训练、推理到后期强化训练的全生命周期,满足了大规模AI计算对性能、可靠性和迭代速度的苛刻要求。通过Pinterest、Uber、Roblox等行业顶级企业的应用案例,可见这一技术组合已成为现代AI平台的基石。未来,随着算法创新和硬件升级不断推进,持续完善和优化的开源堆栈将进一步释放AI计算潜力,驱动更广泛的智能应用落地。
。