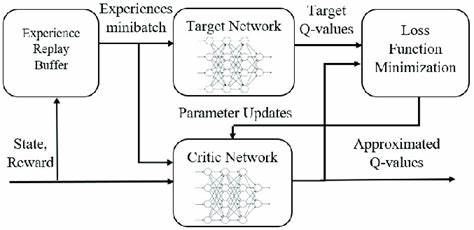
随着人工智能领域的快速发展,强化学习作为一种模拟智能体通过环境交互获取最优策略的重要方法,正逐渐成为科研和实际应用的关键技术之一。然而,在强化学习的实际训练过程中,数据采集的效率和质量直接影响模型的训练速度和效果。经验回放池(Experience Replay Pool)作为一种提升数据利用率的重要工具,被广泛应用于深度强化学习中。多进程经验回放池的提出,旨在通过并行化环境交互和数据管理,极大地提升数据收集的效率与均衡性,从而推动强化学习研究迈上新台阶。经验回放池的核心思想在于将智能体与环境交互产生的状态、动作、下一状态、奖励以及终止标志等信息进行存储,形成训练数据集,在后续的训练中反复利用。传统的经验回放池多以单进程形式实施,存在数据采集效率低、环境交互速度受限以及数据分布不均等问题。
多进程经验回放池通过将环境实例分配至多个进程中,实现环境相互独立且并行运行,充分利用多核CPU资源,加快数据采集。该技术利用Python的multiprocessing模块进行进程管理和共享内存设计,确保多进程间能够安全高效地访问和更新共享数据结构,避免数据竞争和冲突。在系统结构设计上,多进程经验回放池分为多个子池,每个进程负责与一个或多个环境交互并管理对应的局部经验数据集合。为了保证整体数据池的大小和数据质量,设计中引入了窗口化管理机制,它能够根据配置的窗口大小动态调整各子池的数据,剔除老旧样本,从而保证数据的新鲜度和多样性。同时,为了平衡各子池间数据量,采用随机化优先存储策略,根据各子池当前长度的倒数概率分配新数据,避免数据集中于某个子池而导致训练样本失衡。此外,多进程经验回放池还支持定期清理旧数据的功能,通过指定清理频率和清理大小,抑制数据池无限增长带来的内存压力,提升系统的长期运行稳定性。
实现方面,核心代码中定义了Pool类,封装了多进程环境管理、数据存储与维护、并发访问控制等关键功能。该类允许用户灵活配置环境实例列表、进程数量、数据池大小以及清理策略。数据存储采用共享列表,通过multiprocessing.Manager实现跨进程数据共享与同步。多进程环境交互函数store_in_parallel运行于独立子进程中,持续执行环境交互并将经验数据通过pool方法存入共享数据结构。采用锁机制确保在随机优先策略下,进程间访问数据计数时的线程安全。用户只需调用store方法启动所有数据采集子进程,后续通过get_pool方法即可方便地获取聚合后的经验数据,用于强化学习模型的训练。
多进程经验回放池的应用为强化学习带来了显著的收益。通过并行化的大规模数据采集,训练过程更快速且样本覆盖更全面,有助于提高策略学习的效果和鲁棒性。在实际场景中,用户可以根据具体需求调整进程数量和窗口大小,灵活适配不同计算资源和训练目标。此外,该设计思想也为未来扩展功能奠定基础,如优先经验回放、异步训练等方向。值得注意的是,设计合理的多进程同步机制和数据管理策略对于系统性能至关重要。不恰当的资源调度可能导致进程阻塞或数据不一致,影响训练质量。
因此,用户在部署时需结合自身硬件环境和算法需求进行调优。总的来看,多进程经验回放池为深度强化学习提供了一种高效且稳定的数据采集解决方案。它有效解决了环境交互瓶颈,提升了经验数据的利用率,并为复杂任务的训练提供了坚实的数据支撑。未来,随着硬件性能的提升与算法的演进,多进程数据管理技术将在强化学习领域发挥更加重要的作用,助力人工智能迈向更高水平的智能决策能力。