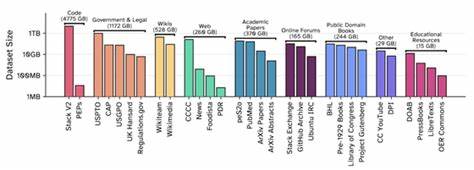
近年来,人工智能领域,尤其是大型语言模型(LLM)的发展日新月异。在模型规模不断扩大的同时,训练数据的质量和数量成为推动性能突破的核心因素。然而,在数据采集方面,透明度逐渐降低,版权争议和法律诉讼频繁出现,使得公开且合法的训练数据集尤为珍贵。Common Pile v0.1的发布正是在这样的背景下,带来了极具意义的变革。EleutherAI作为开源社区的先驱者,四年半以前曾发布过Pile数据集,当时以800GB的多样化文本成为迄今为止最大规模的预训练文本语料库之一。Pile独创性地引入了医学文献PubMed和问答社区StackExchange作为训练素材,并首次尝试将代码与自然语言混合训练,极大推动了开源AI模型的发展。
Common Pile v0.1则是Pile的继任者,由EleutherAI联合多所顶尖学术机构和科研团队共同耗时两年精心整理完成,规模高达8TB。与过去的数据集区别最大的是,其所有内容均来自公开许可或公共领域文本,保障了法律合规性与开放性,在开放科学精神指引下,支持更多研究人员和开发者参与到LLM研究中来。公开释放大规模数据集的核心价值体现在多方面。首先,科学研究要求完全透明和可重复的实验条件,而训练数据的保密严重限制了对模型记忆特性、隐私风险、数据编排策略、训练动态以及偏见公平性的深入探讨。通过共享语料库,不同架构和算法能够在相同数据环境下进行公平对比,例如RWKV和Mamba模型均使用了Pile作为基准,这极大促进了技术创新并减少了学术资源浪费。其次,当前大量语言模型能力的测试依赖于复杂且难以复制的基准,如果数据不透明,存在数据泄露的可能,从而影响结果的真实性和公信力。
Common Pile v0.1的开放许可体系通过严格的版权核查流程确保数据合法性,同时推动业界建立更高水平的责任机制。过去几年,围绕机器学习数据使用的诉讼事件频发,虽然未根本改变数据采集模式,却显著降低了公司和组织的信息公开意愿。对比2020至2022年间模型发布时的透明度,2023年以后多家知名机构明显减少了其预训练数据的披露,即便是像OpenAI、Anthropic和Google DeepMind这样的大厂,也逐渐减少了对数据来源和实验细节的描述。反观EleutherAI、Hugging Face、AI2等开放科研组织,依旧坚持开放和合作的原则,积极推动数据和模型的共享。Common Pile在维护开放精神时也面临诸多挑战。定义“开放许可”并非易事,不同用途对许可的适用性有不同标准。
为此,团队咨询了法律专家,并依据Open Knowledge Foundation的开放许可定义,涵盖不仅仅是宽松许可,还有诸如Share-Alike的共用许可。这种许可体系为使用者提供了全面的使用、研究、修改和再分发权利。识别数据许可更是艰难,由于自动工具尚不成熟,团队主要依赖可信来源的元数据和人工辨别,特别是代码库部分通过Software Heritage Foundation和BigCode项目等先进工具实现了许可的准确筛查。公共领域作品的归属情况更为复杂,全球不同法域对版权的有效期限和归属有差异,缺少统一标识。尽管Creative Commons公共领域标记(Public Domain Mark)有所帮助,但仅部分作品配有该标签,团队需从大型馆藏如美国国会图书馆、互联网档案馆等处获得数据,并手工确认其公共领域状态。项目期间,EleutherAI与各界合作开发了丰富的数据提取和许可识别工具,这些工具部分已开源并计划持续发布。
2024年6月,项目团队与Mozilla共同举办了数据集研讨会,汇聚开源AI初创企业、非营利实验室和民间组织,共同探讨开放数据领域的发展最佳实践,成果发表在论文“Towards Best Practices for Open Datasets for LLM Training”中。此外,团队还利用Whisper语音转文本技术和文档转换工具Docling,提升了音频及扫描文本数据的可用性和质量。Common Pile中包含了超过29万册公共领域数字化图书,这些大多采用早期光学字符识别(OCR)技术,当前先进的OCR模型如Docling和Surya的应用将大幅提升文本准确率。团队希望通过与图书馆、博物馆和档案馆的紧密合作,打造更多高质量的开放数据集,实现文化遗产的数字化共享。为了验证开放许可数据的训练效果,团队基于Common Pile训练了两个7亿参数规模的模型——Comma v0.1-1T和Comma v0.1-2T,分别训练1万亿和2万亿tokens。测试表明,这些模型在性能上能够匹敌使用非许可数据训练的领先模型。
有小范围消融实验显示,相较于一些较小或许可受限的数据集,Common Pile训练的模型表现更优,且在与Pile和OSCAR等数据集的比较中表现相当,尽管相较于FineWeb仍有一定差距,但这主要是因为FineWeb拥有更海量的数据基础,能够从更大数据池中筛选高质量内容。随着公开许可资源的不断增加,未来基于开放数据的模型质量预计将逐步向顶尖水平靠拢。此次8TB规模的Common Pile v0.1,是一个起点而非终点。团队已经规划未来发布更大规模、更优质的版本,探索尚未充分利用的开放许可资源,推动LLM训练数据的进一步升级。同时,后期训练数据的开放也将使得模型适应性更强,更贴合多样化用户需求。Common Pile的成功彰显了开放科学和开源社区在人工智能发展中的不可替代作用。
它不仅为研究者和开发者提供了合法、透明、高质量的数据基础,也促进了模型性能的公平竞争,推动技术创新与应用拓展。与此同时,它强调了开放许可体系的重要性,呼吁更多机构加入开放数据生态的建设,携手推动AI的健康、高效、负责任发展。展望未来,隐私保护、版权合规与数据可用性之间的平衡将是关键课题。随着自动化数据处理和高级标注工具的日益完善,开放许可数据集的构建将日益高效和精准。通过跨界合作,文化遗产信息化和AI技术深度融合潜力巨大,将使大量历史文献、社会科学资源甚至音视频材料成为训练素材,为人工智能赋能多领域应用提供坚实基础。Common Pile v0.1的发布,不仅是数据集本身的丰厚成果,更是开源精神与科研共享理念的具体体现。
无论是推动学术研究的深入,还是促进商业和社会应用的创新,都意味着一个更加开放与共赢的AI未来正逐步展开。它激励全球AI社区秉持透明、合规、共建的价值观,携手探索智能时代的新边界。作为一个新兴但充满潜力的训练语料库,Common Pile v0.1的持续发展将进一步推动开放数据标准建设、提升AI公平性并助力全球科技创新,成为引领未来语言模型研究的重要基石。









