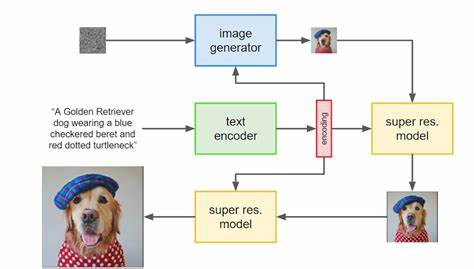
近年来,随着人工智能技术的飞速发展,文本到图像的扩散模型已成为生成式人工智能领域的研究热点。这类模型能够根据自然语言描述生成高质量的图像,广泛应用于数字艺术、游戏开发、广告创作等多个场景。然而,尽管生成质量令人瞩目,这些模型背后的计算资源消耗极为庞大,尤其是在处理大量相关文本提示时,重复计算造成的效率瓶颈日益显著。为应对这一挑战,研究者们开始探索在文本到图像扩散过程中复用计算以提升生成效率的新思路。 文本到图像扩散模型的工作机制通常基于渐进式去噪过程,即模型以逐步减少噪声的方式从随机噪声中重建目标图像。该过程分为多个去噪步骤,逐步从粗糙的结构到细节精确地成型图像。
这一"由粗到细"的特性为计算复用提供了天然契机:当多个文本提示语义相近时,它们在初期扩散步骤中生成的图像大体结构及信息具有高度相似性,允许共享部分计算以避免重复处理。 研究者提出了一种创新的无监督计算复用方法,核心思想是对大量文本提示进行语义聚类,通过识别相似语义的文本组,集中处理其前期扩散步骤,减少冗余计算投入。具体来说,这种方法不需要额外的训练,便能直接应用于现有扩散模型架构,极大降低了集成难度与门槛。 同时,该方法借助了基于图像嵌入(image embeddings)的条件生成框架,例如UnClip模型,进一步优化了扩散步骤的资源分配。UnClip将文本条件映射成图像嵌入,为计算复用提供了更精确的语义判别基础,从而提升共享计算的质量和效率。 在大规模图像生成任务中,这一技术展现出显著优势。
试验结果表明,通过前期去噪步骤的共享,整体计算成本得以大幅度降低,同时生成图像的视觉质量不仅没有下降,反而得到一定程度的提升。每一次实验均显示,计算复用不仅提升了资源使用效率,也减少了环境负担,符合当前技术绿色可持续发展的趋势。 该计算复用方法的应用场景多样,尤其适合于需要生成大量语义相关图像的设计工作室、广告公司以及内容创作平台。通过语义聚类的策略,用户可以一次性提交大量提示,系统在背后自动识别并共享相关计算资源,实现批量高效生产。在节约硬件成本的同时,提高了生成速度,极大提升了创作体验与产出效益。 此外,该技术的无训练特性意味着它能够无缝集成到现有主流扩散模型和生成流水线中,无需复杂调整即可实现显著性能提升。
由此为各类创新应用和商业落地提供了坚实基础,推动人工智能图像生成技术的普及与深化发展。 从未来发展角度看,计算复用策略为扩散模型的进一步优化提供了新思路。通过更细粒度的语义分析和动态调度机制,可以实现更加智能化和自适应的计算分配,甚至结合强化学习或元学习方法,不断自动发现和挖掘计算共享潜力。这将有望催生新一代高效、绿色、智能的生成模型。 总之,文本到图像扩散模型中的计算复用技术不仅极大提升了图像生成的效率和质量,还推动了产业可持续发展。它有效缓解了计算资源消耗带来的经济与环境压力,让更多创作者能够低成本、高速度地实现创意构思转化为视觉艺术作品。
未来随着技术的不断完善和应用的深入,计算复用将成为文本生成视觉内容领域的核心竞争力,助力智能创作迈入全新时代。 。