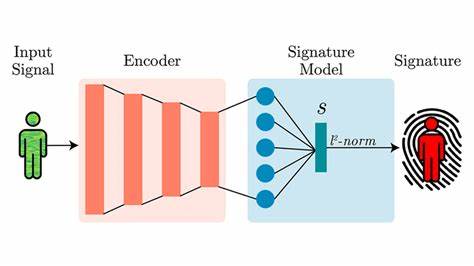
在当今数据驱动的时代,企业和机构在运营和客户关系管理中,往往面临大量用户自由输入的文本数据。尤其是在填写职位、雇主等信息时,用户的输入异常多样且混乱,这给数据分析和精准服务带来了极大挑战。比如有人填写“护士”,有人写“急诊护士”,有人用“注册护士(RN)”,还有人写“家庭护理”,这些名目繁多又风格各异的职位信息如果不加以规范,难以为企业的用户分类、营销策略以及服务优化提供准确依据。幸运的是,随着大型语言模型(LLM)嵌入技术的飞速发展,我们找到了用语义向量空间有效统一和规范用户数据的先进方法。本文将详细解读如何借助LLM生成的嵌入向量和余弦相似度计算,实现针对庞大异构文本的高质量职位数据规范化。用户自由文本数据的复杂性主要体现在多样性和不一致性,传统依赖正则表达式、人工规则或者关键词匹配的方式不仅费时费力,而且难以涵盖用户输入的多样语言习惯。
而LLM嵌入为文本赋予了数值化的语义向量,这种向量化表示能够捕获语言的深层含义与语境联系,使得不同表述但语义相近的文本在向量空间中彼此靠近,展开了前所未有的规范化可能。规范化的前提是定义一个有限的规范类别集,针对职位信息来说,可利用权威的人力资源数据库如美国劳工部支持的职业信息网(O*NET),该数据库汇聚了职位名称、技能需求和别名等信息,提供了一个庞大且系统的职业类别参考。通过整合O*NET中职位、替代职位和简短职位名称,将它们合并为包含“aka”(也称为)的长职位语句,可以构建出多样表述映射至同一规范职位的基础语料库。随后,采用专门针对职位匹配优化的语言模型,如基于all-mpnet-base-v2微调得到的JobBERT-v2,对这些长职位名称进行编码并生成标准化的语义向量。用户输入的任意职位自由文本同样经过相同模型编码,转化为向量后,可以通过计算其与O*NET职位向量集的余弦相似度(向量点积),快速定位语义最接近的标准职位类别。余弦相似度在向量空间中的值越高,表示两个职位描述在语义上越相似,因此实现了自由文本的自动归类,弥补了传统基于字符串匹配的不足。
大批量用户数据的处理中,针对数万条用户输入和数千个职位参考向量,利用GPU加速的张量运算能够有效计算所有可能的匹配关系,保证时效性和准确度。实践中,以政治科技领域的竞选捐款数据为例,运用此思路成功将捐赠者填写的职位名称,映射到了O*NET定义的规范职位上。诸如“律师”被匹配为“律师”,模糊的职位如“code ninja”被智能关联为“计算机程序员”,甚至职位缩写、别称均获得良好对应,展现了技术的强大适应力。同时,使用主成分分析(PCA)可视化高维度嵌入空间,验证不同职位嵌入的分布及用户输入数据的语义聚类关系,为业务数据分析提供直观依据。该方法依托语义理解,不涉及生成文本或依赖外部API,体现了自主可控和无人工干预的优势。不过,规范化仍然存在改进空间,比如极端模糊或多义职位描述的匹配效果可能偏差,需结合业务场景调整语料库构建策略和模型参数。
除了职位领域,这一基于语言模型嵌入的规范化方法,也同样适用于其他自由文本字段,如教育背景、专业技能、产品描述等。通过深度语义匹配,能够极大提升数据的一致性、准确性和后续数据驱动应用的价值。总结来看,大型语言模型生成的嵌入向量技术,为复杂用户自由文本数据的规范化提供了高效且智能的解决方案。借助权威数据集构建规范类别,通过专门调优的语义编码模型,配合向量空间相似度计算,不仅避免了繁琐的人工规则设计,还极大提升了处理规模和准确率。未来,随着模型性能进一步提升及硬件加速能力增强,基于LLM嵌入的自动规范化定将成为数据治理和智能运营不可或缺的核心技术路径。企业和技术团队应抓住这一趋势,实现自由文本数据的标准化转化,为精准用户洞察和个性化服务创造坚实基础。
。