随着人工智能领域的飞速发展,大型语言模型(LLMs)在自然语言理解与生成方面展现出卓越的能力。尤其是在推理任务上,这类模型的表现近年来取得了显著提升。然而,传统依赖人工标注的示范数据进行监督训练的方法受到规模限制与认知偏差的影响,难以进一步释放模型的潜在推理能力。DeepSeek-R1的出现,正是致力于通过纯强化学习(Reinforcement Learning, RL)框架,突破这一瓶颈,激励LLMs自我进化推理策略,从而实现更高水平的智能表现。DeepSeek-R1的研发团队基于DeepSeek-V3 Base模型,创新性地使用Group Relative Policy Optimization(GRPO)算法设计了一个无需依赖人工标注逻辑轨迹的强化学习训练体系。这一体系通过仅基于任务最终正确性的奖励信号,驱动模型自发探索更复杂、多样且高效的推理路径,而非简单模拟人类预设的解题方式。
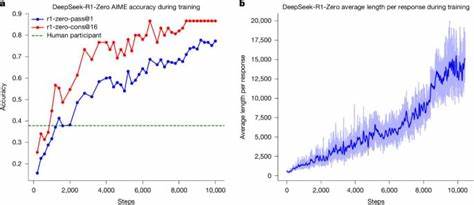
该方法不仅节省了大量监督数据的采集和标注成本,更重要的是突破了人类推理范式的局限,为模型发掘潜在更优策略铺平了道路。DeepSeek-R1训练的第一个阶段产物为DeepSeek-R1-Zero,该模型在美国数学竞赛AIME 2024等严苛基准测试上表现优异,单次尝试准确率由训练初期的15.6%飙升至77.9%,结合自洽解码进一步提升到86.7%,整体超过了所有人类参赛者的平均成绩。除此之外,在编程竞赛及理工科研究生水平的生物、物理、化学题目上,DeepSeek-R1-Zero同样展现了卓越的推理能力,体现了强化学习对复杂认知任务的适用性和有效性。在训练过程中,模型逐渐学会加长推理输出,体现出类似人类反思和验证策略的行为。它会主动进行答案确认、检验中间步骤、探索多解方案,表现出明显的"自我进化"特征。令人印象深刻的是,训练曲线中出现"顿悟时刻",模型输出中"wait"(等一下)一词的使用频率显著攀升,暗示其开始进行时间延展的思考和自我监控,进一步佐证其复杂推理能力的生成。
尽管如此,DeepSeek-R1-Zero面临着语言混用(中英夹杂)、可读性偏差以及任务专一性过强等问题。为此,研发团队构建了多阶段训练框架,结合拒绝采样、强化学习和监督微调等技术,逐步进化出DeepSeek-R1最终模型。借助数千条冷启动数据,团队引导模型向更符合人类交流习惯的"会话式推理"倾斜,显著提升了语言一致性和指令遵循能力。此后,加入广泛推理和非推理数据的监督微调,让模型在维持推理优势的同时,实现了写作与开放领域问答等任务表现的均衡发展。最终,通过第二阶段强化学习,模型不仅在保持推理能力的基础上,更加契合人类喜好,增进了友好性与安全性。DeepSeek-R1在多项国际权威评测基准如MMLU、DROP、C-Eval、Codeforces等中表现优异,证明了其多领域适应性和高效推理能力。
其衍生出的精简蒸馏版本,为学术及工业界便捷使用先进推理模型创造了条件。DeepSeek-R1背后的GRPO算法,为训练过程带来了计算效率和效果的双重提升。相比传统的PPO,GRPO通过组内采样输出的相对优势估计,直接优化策略参数,无需额外价值网络,简化了训练流程,节省了资源开销。模型训练时,采用了融合精确规则检验类奖励与基于模型的偏好奖励,确保推理任务信号准确可靠,减少奖励欺骗风险,同时兼顾了生成内容的安全性和有用性。这种混合奖励设计有效支持了推理和开放领域多样任务的协同训练。值得关注的一个限制是DeepSeek-R1当前的结构化输出能力仍有待提升,目前尚不能有效集成诸如搜索引擎、计算器等工具强化推理过程。
未来版本计划通过设计相应的强化学习环境,赋予模型工具使用能力,实现更高性能和实用价值。此外,模型在语言混用、多语言处理及提示工程方面存在敏感性和效率不足,需继续优化以适应更广泛的应用场景。纯强化学习方法在依赖高质量奖励信号方面的局限也提醒研究人员,如何设计更通用、稳健的奖励机制仍是亟待突破的难题。DeepSeek-R1的成功展现了强化学习在推动大型语言模型深化推理技能上的潜力,它开辟了一条减少人工依赖,依靠试错和逐步改进实现智能自主演化的新路径。其训练所得先进推理能力不仅超过部分专业人类参赛者,还体现了模型对复杂逻辑、多步骤任务的深刻洞察力。随着相关技术不断迭代成熟,可以预见未来多模态、工具增强结合的强化学习驱动模型将在科学研究、教育及工业智能自动化等领域发挥更重要作用。
总之,DeepSeek-R1代表了大型语言模型强化学习应用的最新突破。它通过纯RL激发模型复杂推理策略的自然生成,挑战了人类思维范式,为实现更加自主高效且具备多元推理能力的AI系统提供了宝贵经验。未来进一步完善奖励设计、提升语言和任务的适应性,将推动此类模型在更广泛领域释放潜力,助力人工智能迈向更智能、更可信和更全面的未来。 。