在人工智能驱动软件开发迅猛演进的当下,KAT 系列以其面向工程化的设计与大规模 Agentic 强化学习策略,正在成为代码智能领域的重要力量。KAT-Dev-32B 作为开源的 32B 参数模型,面向软件工程任务展现出均衡且可复现的能力;而旗舰变体 KAT-Coder 则在 SWE-Bench Verified 等基准上取得显著领先,标志着规模化 Agentic RL 在代码生成与交付方向的实际价值。 KAT 系列的核心价值来自于系统化训练流程和工程级别的 RL 基础设施。不同于仅靠监督学习微调模型的传统路径,KAT-Dev-32B 与 KAT-Coder 采用了多阶段训练策略:在 Mid-Training 阶段注入工具使用、多轮交互与代码知识,在 SFT 阶段以人工标注的交付轨迹打磨模型的端到端能力,并引入 Reinforcement Finetuning(RFT)作为 SFT 与自由探索型 RL 之间的稳健桥梁。这样的设计既提升了样本效率,也在后续的 Agentic RL 中显著降低了不稳定性。 Mid-Training 并非简单的预训练延长,而是有针对性地构建模型作为"LLM 代理人"的基础能力。
团队在封闭沙箱中为数千种工具创建真实执行记录,累积多回合对话数据,注入领域化代码知识,并引入大量真实的 pull request 与 commit 数据以强化模型对代码演化与协作流程的理解。通过覆盖工具调用、记忆管理、指令跟随与常见使用场景,Mid-Training 为后续 SFT 与 RL 提供了更稳定、更具泛化力的冷启动模型。 监督微调阶段团队精心整理了八类用户任务与八大编程场景,从功能实现、缺陷修复到性能优化、测试生成与部署配置,力求让模型在多维度的软件工程实践中具备可验证能力。在 SFT 之后引入的 RFT 创新性地使用"教师轨迹" - - 由人类工程师标注的高质量交付路径,作为 RL 探索的参考,从而在模型开始自由探索之前给出稳健的探索指引。与直接赋予绝对奖励不同,RFT 更加关注样本与"地面真值"之间的相对差异,并在 rollout 过程中实时监督生成质量,及时终止偏离既定交付路径的生成。这一方法显著提升了 RL 的样本效率与训练稳定性。
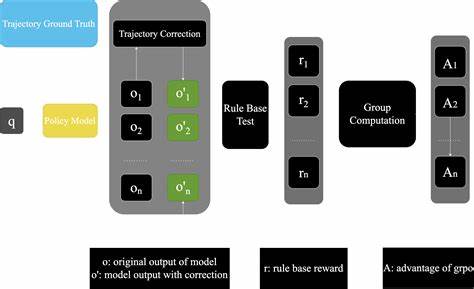
规模化 Agentic RL 的工程挑战不可小觑。要让模型在复杂的多工具、多回合、多分支的轨迹树上高效学习,需要解决非线性轨迹历史的效率计算、有效挖掘模型内在信号、以及搭建高吞吐量的异构计算流水线。针对这些难点,KAT 团队提出了若干关键技术:前缀缓存用于加速对数概率计算,基于熵的轨迹树剪枝用于在固定计算预算下优先保留信息量最大的节点,以及名为 SeamlessFlow 的中间层架构以实现训练与代理逻辑的解耦和跨集群的任务调度。 熵驱动的树形剪枝在工程上尤为重要。将采样轨迹压缩为前缀树后,每个节点代表共享的前缀历史,而边则对应一段令牌序列。通过估计节点信息量与可达概率,团队在预算限制下逐步展开最有价值的节点,保留与工具事件或记忆事件相关的结构性区域,以确保局部上下文的连贯性。
此策略在显著降低冗余计算的同时,保留了大部分有效训练信号,从而带来可观的吞吐率提升和算力成本下降。 在 RL 基础设施方面,SeamlessFlow 的设计思想是将轨迹树管理从代理实现中抽离出来,作为独立的中间层服务。这种解耦既降低了系统复杂度,又便于在多种执行环境之间统一调度与扩展。结合 tag 驱动的调度机制,SeamlessFlow 能够在异构集群中高效分配任务,减少流水线空转,维持高并发训练效率。与此同时,统一的环境接口使得来自不同来源的可验证任务(如带有可执行环境与单元测试的 Git 分支)能够低成本接入 RL 流程,进一步丰富训练信号。 数据建设上,KAT 团队不仅采集公共仓库的 PR 与 issue,还系统化地生成可执行环境镜像与测试用例,以确保训练过程中的每一次尝试都能被自动评估。
更重要的是,团队引入了匿名化的企业级代码库作为训练素材,补足开源仓库常见的简单项目偏差。来自真实工业系统的复杂业务逻辑、多语言混合项目与跨仓库依赖为模型提供了更具挑战性的训练场景,从而提高了模型在生产级问题上的鲁棒性与实用性。 在评测层面,KAT-Dev-32B 在 SWE-Bench Verified 上取得了 62.4% 的 resolved 率,并在开源模型中位列前五,这一结果证明了 32B 参数量级在结合工程化训练流水线后,可以实现高性价比的编码能力。旗舰 KAT-Coder 则凭借规模化 Agentic RL 与更大规模的训练资源,将 resolved 率提升至 73.4%,显示出在同一训练范式下更高容量模型的明显优势。 值得关注的是规模化 Agentic RL 所带来的新兴行为。团队观察到模型在多轮交互中的平均回合数下降了约 32%,表明模型在寻求更短、更高效交付路径方面表现出优先倾向。
此外,KAT-Coder 在训练后展现了并行工具调用的能力,突破了传统按序调用工具的限制,能够同时发起多个工具请求以并行处理子任务。研究团队认为,这种现象源于轨迹树结构中对更高效路径的自然选择以及熵剪枝保留高信息量、多分支节点的机制。 从理论角度看,轨迹树为模型提供了一个隐含的效率优化目标。较短的路径在树结构中被更多轨迹共享,从而在训练过程中产生更强的优化信号。同时并行工具调用为树结构引入更多分支,训练过程中能够并行探索这些分支,逐步学习到批量处理或并发处理的策略。这些 emergent 行为不仅提升了交付效率,也为未来构建协作式多代理系统奠定了可能的方向。
在开放获取方面,KAT-Dev-32B 已经开源并在 Hugging Face 上发布,便于研究者与工程师复现与改进。对于希望使用旗舰模型的企业用户,KAT-Coder 可通过 StreamLake 的平台申请 API Key 并通过 Claude Code 的集成开始使用,相关接入文档与端点配置流程已提供便捷指引,降低了从实验室到生产环境的迁移成本。 面向未来,KAT 团队计划在工具深度整合、编程语言覆盖、协作式编码以及多模态代码智能上持续投入。通过将模型与常用 IDE、版本控制系统以及开发工作流更紧密地连接,并探索模型在图示、界面设计与调试截屏等视觉信息上的理解能力,KAT 希望让代码智能不仅能写代码,还能理解设计、协作与部署的全流程。 KAT-Dev-32B 与 KAT-Coder 的实践证明了在软件工程领域,单纯提升模型参数量并不足以解决所有问题。更重要的是围绕真实工程场景构建高质量训练数据、采用分阶段训练策略以及设计面向规模化 RL 的工程化基础设施。
通过这些方法,Agentic RL 不再是理论概念,而成为能在复杂、可验证的软件交付任务中稳定产出价值的技术路线。 对于开发者与企业来说,值得关注的不仅是模型的 benchmark 分数,更在于能否将这些模型无缝嵌入现有开发流程,提升团队效率并降低维护成本。KAT 系列在开源与商业化接入之间建立了双向通路,既鼓励学术与社区在 Hugging Face 上创新,也通过 StreamLake 与 Claude Code 的商业接入为工业级应用提供支持。 总之,KAT-Dev-32B 与 KAT-Coder 代表着代码智能从单点能力向工程化、可部署的代理系统迈进的重要一步。随着轨迹树技术、熵驱动剪枝与 SeamlessFlow 异构调度机制的成熟,未来的代码代理将更擅长高效交付、并行工具协作与多轮复杂任务解决,为软件开发带来更高的自动化水平与生产力提升。对于关注代码智能和 Agentic RL 的研究者与从业者而言,KAT 的方法论和开源实践值得深入研究与借鉴。
。