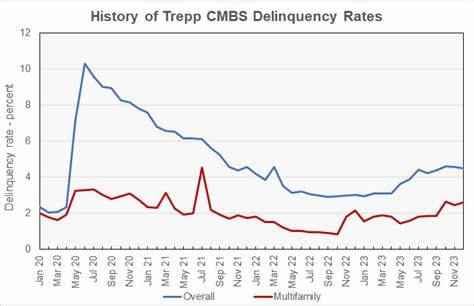
在大型语言模型(LLM)领域,随着模型规模不断扩大,生成文本的计算复杂度和时延成为核心挑战之一。KV缓存(Key-Value缓存)技术因其能够高效复用计算结果,逐渐成为提升推理效率的关键利器。尽管KV缓存的概念并不复杂,但其实现细节和优化策略却值得深入探讨。理解并掌握KV缓存对于从零实现高效的LLM推理代码尤为重要。所谓KV缓存,本质上是将每一时刻生成文本的中间计算结果,即键(Key)和值(Value)向量存储下来,避免在后续生成步骤中重复计算。这主要是解决自回归生成过程中,上一步已计算的内容反复被重新编码造成的性能瓶颈。
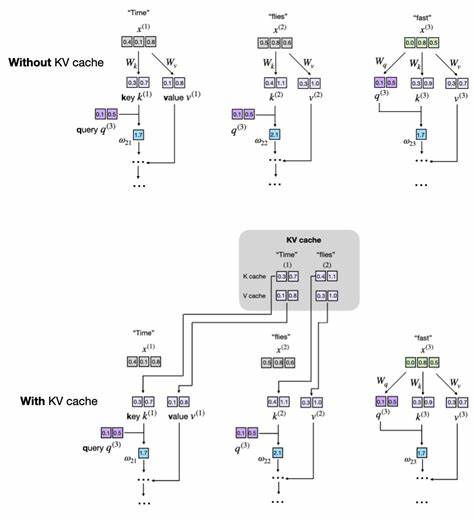
以一句简单的文本“Time flies fast”为例,在传统推理过程中,每生成一个新词,模型都需要重新计算此前所有词的键和值向量。这导致了计算冗余,也加大了推理时间。KV缓存机制则会在首次生成“Time”时计算并保存对应的键值向量,后续生成“flies”及“fast”时仅针对新增词重新计算,而先前缓存的向量被直接复用,大幅减少了重复计算的开销。该机制虽然在推理时非常有效,但由于缓存需要额外内存存储键和值向量,也带来了内存占用的挑战,且不适合训练阶段使用。KV缓存的核心体现是在注意力机制的多头自注意力模块中。在多头注意力的实现中,通过线性变换将输入的词嵌入映射为查询(Query)、键(Key)和值(Value)向量。
传统做法每一步都重新计算全部的K与V,KV缓存则是引入额外缓存变量来保存已生成词的K和V。实现上,可以在多头注意力模块构造函数中注册缓存缓冲区(register_buffer)用于存储键和值。这些缓存通过判断是否为空来决定是否初始化,随后每步对新词的K和V进行计算并拼接到缓存中,形成完整的缓存序列。如此一来,后续步骤调用时即可直接使用缓存而不必重新计算所有词的K和V。值得注意的是,缓存需要在每次新的文本生成前手动清空,防止模型使用上一段文本的状态而导致生成混乱。关于KV缓存在整体模型中的管理,通常会为每个注意力模块分别维护缓存空间,而模型还需保存当前序列的位置计数,确保新计算的K和V正确地接续缓存,以保持注意力机制的时序一致。
此外,模型的前向传播函数需要新增参数来控制是否使用缓存,从而切换传统全量计算和增量缓存计算模式。文本生成函数也需相应调整。启用缓存时,首次生成需要将完整上下文传入模型以初始化缓存,后续生成仅需将新生成的最后一个词作为输入并利用缓存即可。未启用缓存时则始终传入全量输入序列。性能层面,KV缓存不仅在理论上降低了推理复杂度,从原始的平方级别缩减为线性,实际测试也体现出显著加速效果。在一款具备亿级参数规模的小模型中,缓存技术实现了约五倍的推理速度提升。
然而,KV缓存增加的内存需求同样不可忽视。缓存随着生成序列增长线性扩大,若缺乏有效管理,可能导致内存资源被快速耗尽。在工业界实践中,缓存管理通常结合滑动窗口裁剪策略,仅保留最近若干个词的K和V,既保持推理速度又控制内存占用。进一步提升缓存性能的优化手段包括预先分配固定大小的缓存张量,避免频繁的拼接操作引发的内存碎片和分配开销。通过将缓存视为固定长度的循环缓冲区,可以避免重新分配并确保高速访问。此外,将缓存操作与设备内存管理紧密结合,如合理利用GPU张量缓存和流式计算,也能有效减少延迟。
KV缓存技术虽然主要用于推理,但是其实现细节与深度影响了整个大型语言模型生态。理解其底层机制,不仅帮助提升推理速度,也为模型部署和优化带来启发。对于初学者,推荐先从简洁的纯Python实现开始,逐步引入缓存机制,随后深入优化。在线教程和开源代码示例为学习者提供了极佳的实践路径。展望未来,随着LLM向更长上下文和更大参数量发展,KV缓存的设计理念将继续演进。例如结合稀疏注意力机制、分布式缓存设计以及硬件加速优化,都将成为重要方向。
KV缓存的设计和优化是连接模型理论与高效工程实现的桥梁。通过主动管理好多头注意力中的中间状态,不断调整缓存策略,可以同步兼顾模型精度、推理速度和资源消耗。总之,KV缓存是大型语言模型推理性能提升的重要工具,既能解决自回归生成的计算冗余,也带来了新的工程挑战。借助正确理解和实现KV缓存机制,开发者能够构建出更高效、更实用的语言生成系统,满足日益增长的应用需求。未来,KV缓存相关的技术和工具必将持续丰富,为AI文本生成领域的深化突破提供坚实保障。