随着大数据时代的到来,海量信息的高效处理成为现代计算机科学中的关键难题。布隆过滤器(Bloom Filter)作为一种空间高效的概率型数据结构,在快速判断元素是否存在于集合中扮演着重要角色。通过使用布隆过滤器计算器,可以帮助用户准确规划过滤器参数,实现性能与空间利用的最佳平衡。本文将深入解析布隆过滤器的原理、核心参数以及如何利用计算器进行科学设计,助力开发者和技术人员提升数据处理效率。布隆过滤器最早提出于1970年,是一种基于位数组和哈希函数的概率型数据结构。其最大的特点是空间利用极高,能够在极少的存储空间内快速判断元素是否属于特定集合。
具体而言,布隆过滤器包含一个长度为m的位数组,初始时所有位均为0。当插入元素时,利用k个不同的哈希函数计算出k个位置,将对应位设置为1。查询时,同样计算k个位置,如果所有对应位均为1,则判断元素“可能存在”;如果任意一位为0,则元素“必定不存在”。这种方式带来了极快的查询速度和显著的存储节省,但也意味着存在一定的误判几率,即假阳性率(false positive rate)。误判率是布隆过滤器设计中的核心指标,它影响着系统的准确性和效率。假阳性率越低,需要的位数m就越多,哈希函数个数k也需调整,以达到最佳效果。
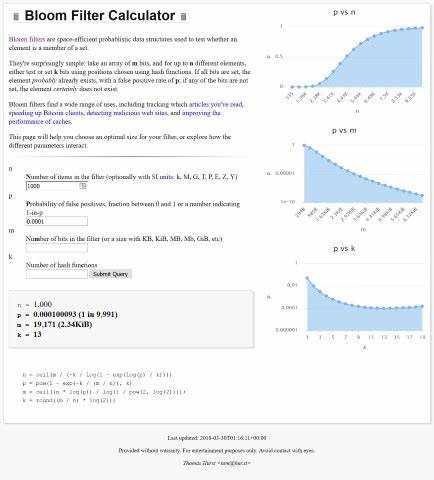
恰当选择n(存储元素数)、m(位数组大小)、k(哈希函数数量)和p(假阳性率)四个参数,能够极大提升过滤器的性能。布隆过滤器计算器应运而生,通过输入实际需求参数,自动计算出最优的m和k值。用户只需输入预期存储元素数量n及可接受的假阳性率p,计算器便会结合数学公式输出最合适的位数和哈希函数数量。例如,当n为4000,p为0.0000001时,计算器推荐的位数约为134191位(约16.38KiB),哈希函数数量为23。这保证了极低的误判率,同时节省了宝贵的存储资源。布隆过滤器的数学基础来自于概率论和信息理论,其误判率p可近似用如下公式计算:p = (1 - e^(-kn/m))^k。
针对不同的n和p,可以反向推导出最优的m和k值。具体计算过程复杂,但布隆过滤器计算器有效地简化了参数选择,使开发者能够快速确定合适的滤波器规模。应用层面,布隆过滤器在多个领域表现突出。它常用于缓存系统中,快速判定某数据是否已缓存,减少冗余请求,提高响应速度。在分布式系统如比特币客户端中,布隆过滤器帮助过滤无关交易,降低节点负载。安全领域亦有广泛应用,能够高效识别恶意网站或邮件,有效防范网络攻击。
通过对布隆过滤器设计的合理规划,系统不仅节省存储空间,还能保证查询效率,适应动态变化的数据规模和业务需求。布隆过滤器计算器同样支持多种单位输入,既可以使用SI单位如k、M、G,也可以采用内存单位如KiB、MiB,方便用户准确输入需求。同时,误判率p的输入也灵活支持小数表示或“1 in p”的反向表示形式,提升使用体验。编写优质、高效的布隆过滤器,需要结合实际业务场景,合理取舍误判率与空间消耗。误判率过高会导致大量误判,影响系统准确性;过低则会浪费存储资源,增加计算成本。利用计算器,可以快速试验不同参数组合,找到性能和资源利用的最佳平衡点。
此外,理解布隆过滤器的限制同样重要。由于其概率性质,布隆过滤器不能删除已插入元素,除非采用计数型布隆过滤器等变体。同时,一旦超过设计容量,误判率将迅速升高,影响系统稳定性。因此,动态调整参数或采用分层设计是实际应用中的常见策略。总结来看,布隆过滤器与计算器的结合,为现代计算系统带来了极大便利。它不仅帮助开发者节省存储空间、提升查询速度,还能灵活适应多种应用场景。
通过深入理解其原理与参数配置,利用布隆过滤器计算器科学设计过滤器,能够有效提升系统整体性能和用户体验。未来,随着数据规模的持续增长与应用需求的多样化,布隆过滤器相关技术必将不断发展,发挥更加重要的作用。