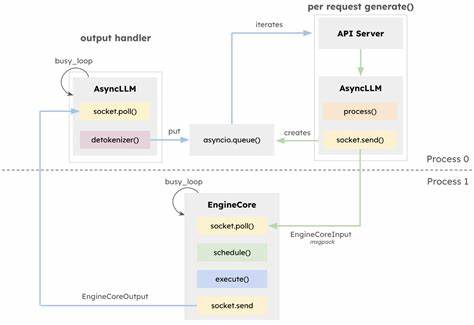
近年来,随着大语言模型(LLM)在自然语言处理领域的广泛应用,推理引擎的性能需求日益增长。vLLM作为深度学习社区中备受关注的推理和服务引擎,凭借其创新设计和高效执行,赢得了广大用户和开发者的青睐。2025年初,vLLM发布了其核心引擎和架构的重大升级版本vLLM V1(以下简称V1),带来了灵活性和可扩展性的显著提升,同时保留了其原有的核心优势。本文将重点解析vLLM V1在架构上的创新及其在AMD GPU环境,特别是AMD Instinct MI300X系列GPU上的优化表现,全面展现其在提升多模态能力和在线推理服务上的突破。V1版本采用了异步执行模型,将CPU密集型任务如文本的Token和Detoken化、图像预处理与GPU密集的模型推理流程进行了有效分离。这种设计通过非阻塞方式实现了任务的并行处理,避免了任务之间的相互等待,从而极大提升了算力利用率。
特别是在多模态大语言模型中,预处理阶段往往依赖于大量CPU资源,其对性能的瓶颈作用得以削弱,使整体推理效率获得显著改善。相较于传统的同步处理方式,V1通过高效的异步调度机制,优化了计算资源的分配,确保GPU不因等待CPU任务而空闲。调度器是深度学习推理引擎中的核心组件,决定了任务的执行顺序与资源分配效率。V1版本简化了调度器的设计,统一管理Token分配,打破了以往预填充(prefill)和解码(decode)阶段的严格区分。此创新不仅让调度器更加灵活,还使得诸如分块预填充(chunked-prefill)和前缀缓存(prefix-caching)等高级功能能够默认启用。分块预填充技术通过将Token的处理预算固定,调度器在推理过程中动态分配任务,极大缩短了反馈时间,优化了延迟表现。
前缀缓存则通过缓存已处理的Token信息,避免重复计算,使响应更加迅速。针对多模态大语言模型,V1引入了编码器缓存(encoder cache)和编码器感知调度器,有效解决了以往多模态嵌入(multimodal embedding)处理的僵化问题。多模态模型常涉及连续特征的生成,而传统架构中全注意力机制导致无法拆分处理,进而造成性能瓶颈。新设计将多模态嵌入直接存储在GPU缓存中,极大减少了CPU负载,提升了多模态推理的吞吐量和响应速度。性能测试数据表明,V1在不同请求率(QPS)下均展现出较V0更低的端到端延迟,尤其在高并发环境中优势明显。在线服务中,V1采用的分块预填充带来了显著的快速响应时间优势,用户平均首次Token输出时间(Time To First Token,TTFT)较V0缩短约25%左右。
这样不仅提升了用户交互体验,也帮助服务提供方实现更高效的资源利用。尽管分块预填充会引入一定程度的请求响应时间分布波动,但整体效果依然远超传统调度机制。多GPU环境下,尤其是使用8张AMD Instinct MI300X GPU的配置中,V1凭借改进的调度策略与批处理能力,实现了25%至35%的总Token吞吐率提升,证明其架构变革不仅在单机性能上显著,在分布式扩展性方面也具备强劲实力。值得一提的是,V1版本默认启用了包括torch.compile编译器优化在内的多项先进技术,进一步推动推理效率摸索至新高。AMD ROCm软件团队积极支持V1,将其优化纳入官方ROCm vLLM Docker镜像中,用户无需复杂配置,即可享受性能升级带来的好处。用户若有需求,依旧能够通过环境变量轻松切换回V0版本,保证兼容性和灵活性。
此外,V1还引入了可选的FP8关键值(KV)缓存支持,助力未来更高效的低精度计算优化等待被激活。整体来看,vLLM V1的架构改良不仅满足了当前大语言模型推理对高吞吐量和低延迟的迫切需求,也为多模态协同处理提供了坚实基础。随着模型规模和复杂度不断提升,推理引擎的灵活性、效率以及对多样化计算资源的兼容性成为关键竞争力。ROCm与vLLM开发社区的紧密合作,推动了GPU端推理性能的跨越式进步。展望未来,随着高性能注意力内核和多精度计算技术的融合应用,vLLM必将在支持大规模多模态模型推理、提升AI应用响应速度及用户体验的道路上发挥更大作用。开发者和研究者可通过ROCm AITER GitHub仓库关注项目动态并积极贡献力量,共同推动开源生态持续繁荣。
总之,vLLM V1代表了大语言模型推理技术的一次重要转型。其在异步调度、简化管理、多模态优化及硬件支持上的创新,深刻体现了当代AI推理的技术趋势与发展需求。无论是面向学术研究,还是产业级应用部署,V1都为高效、智能的语言模型服务提供了坚实保障。随着越来越多用户完成从V0到V1的迁移,整个AI推理领域的性能壁垒将被不断打破,迎来更加灵活、高效且富有创新活力的未来。