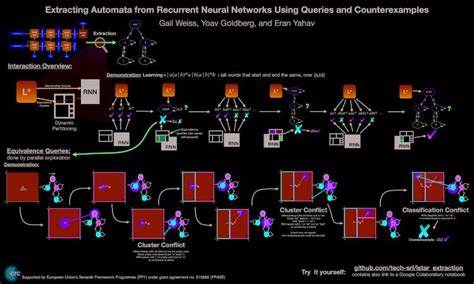
随着深度学习在序列建模任务中的广泛应用,循环神经网络(RNN)在语言、控制与序列预测等场景中表现优异。然而,RNN本质上是连续、分布式的表示,导致其行为难以直接解释与验证。2018年题为《Extracting Automata from Recurrent Neural Networks》的研究有力推动了将这种连续模型映射为离散符号形式的尝试,从而为模型可解释性和形式化验证打开新路径。本文围绕该方向的核心思想、典型方法、实验结论和工程启示展开深入解读,帮助研究者与工程师理解自动机抽取的可行性与挑战,并为后续研究提供实践建议。首先,为什么要从RNN中抽取自动机?离散自动机如确定性有限自动机(DFA)具有结构简单、易于理解与形式化验证的优点。若能从训练好的RNN中导出等价或近似等价的自动机,可以用直观的状态转换图解释模型的决策路径,便于定位错误、证明安全边界或导入符号推理系统。
抽取Automata同时也为语言类任务提供了一种将神经模型与形式语言理论连接的桥梁,使得语法性质、可识别语言类别等问题可以被明确检验。要完成自动机抽取,研究者通常遵循两类核心思路。第一类是基于聚类的方法:先收集RNN在大量输入上的隐藏层激活向量,利用聚类算法将这些连续表示离散化为若干"状态",再构建基于输入符号的状态迁移图,并对所得图进行确定化和最小化以得到DFA。第二类是基于学习与查询的交互方法:将训练好的RNN作为一个"教师",通过向其发出成员查询(membership queries)或等价查询(equivalence queries)来引导像Angluin的L*算法之类的自动机学习器构建DFA。两种方法各有优劣:聚类方法依赖于隐藏向量分布的可分性和聚类超参数,实施简单但可能产生不稳定或过大的DFA;基于查询的方法理论更健全,能够通过反例逐步修正,但在实际应用中等价查询的实现需要近似且代价高。聚类管线的典型流程包括网络训练、轨迹采样、降维与聚类、构建转换图和自动机精简。
训练阶段选择适当的训练集以使RNN学到目标语言的判别边界。轨迹采样需要覆盖尽可能多的输入模式,包括正例与反例、短序列与长序列,以暴露隐藏状态空间的结构。降维常用PCA或t-SNE以便可视化和预处理,聚类则可采用k-means、谱聚类或层次聚类。对每个聚类标签和输入符号的组合统计后继聚类,即可建立离散化的状态转移关系。最后通过确定化与Hopcroft最小化等传统自动机算法得到更简洁的DFA。衡量结果时会关注DFA与原始RNN在判别上的相似度(fidelity)、DFA本身的准确率以及状态数量和可解释性等指标。
交互式学习管线通常把RNN当作"oracle"提供成员查询;初始的候选自动机会被学习器生成并通过等价查询询问RNN是否被该自动机接受集合所覆盖。如有差异,RNN将返回一个反例序列,学习器据此修正自动机并重复该过程。实际中无法直接进行完备的等价查询时,研究者会用带有启发式生成的反例池或者通过验证集替代等价查询,从而实现近似的L*学习流程。该方法在理论上能更可靠地逼近RNN的行为,特别适合用于验证与安全检查场景。论文与延伸研究通常在一组合成语言(例如Tomita语法等)和简单形式语言任务上验证方法有效性。这些语言因结构明确、可被有限状态机描述而常被用作基准。
实验结论表明,在许多情形下,RNN确实学习了可以被离散化为较小DFA的判别策略,并且通过聚类或交互式学习能够恢复出接近或等价的自动机。但研究也指出若干限制:当语言包含长距离依赖或层级结构(如平衡括号)时,有限自动机无法完全表达目标,而RNN可能采用更复杂的连续策略,这时抽取到的DFA往往仅为近似;不同随机初始化或训练超参数会导致隐藏表示分布差异,进而影响抽取结果的稳定性;聚类方法对聚类数和样本覆盖非常敏感,不恰当选择会产生冗长、噪声较多的状态图。从工程实践角度,若目标是为实际序列模型提供可解释性或安全证明,可采取若干改进策略以提高抽取质量。数据采样策略需刻意覆盖边界样本和罕见路径,保证状态空间中关键吸引子被触达。聚类阶段建议结合时间一致性约束及动态演化特征,而不是仅依赖静态聚类。可以使用谱方法或密度峰值聚类来识别稳定吸引子与周期性轨迹,从而减少噪声导致的伪状态。
另一方向是对RNN训练过程施加离散化友好的正则化,例如在训练中鼓励隐藏状态聚集或在激活范围上施加惩罚,通过诱导更明显的"状态"边界来利于后续抽取。在验证与鲁棒性方面,将RNN抽象为DFA有助于形式化证明某些安全属性。例如可以利用模型检测和符号执行技术在自动机上检验拒绝路径、循环性质或对特定输入模式的响应。抽取后的DFA同时也便于人工审查,工程师可以直观查找不合理的状态转换并反向定位到训练数据或模型权重中去修正错误。在模型压缩与部署方面,若抽取出的DFA较小且能保持高保真度,则可直接用离散模型替代RNN实现轻量化部署,特别适合资源受限的嵌入式系统。自动机抽取研究同时启发了若干更广泛的方向。
一个自然延伸是面向更复杂的自动机形式,例如带输出的Mealy机、带概率的随机自动机或带计数器的自动机,以表达更大类的序列行为。另一个方向是将抽取过程与模型训练联合优化,设计端到端可微的抽取模块或引入符号约束用于指导RNN学到更符号化的表示。研究者也在探索将抽取与程序合成、语法推理或强化学习结合,使得智能体策略能被形式化为可验证的状态机。尽管进展显著,自动机抽取仍面临可扩展性和稳定性挑战。对复杂自然语言或具有深层层次结构的数据,当前方法难以直接生成简洁且语义清晰的自动机。未来工作需要在几方面突破:更可靠的状态聚类与表示学习技术以捕获长期依赖与上下文信息;高效的查询策略与反例生成机制以支持交互式学习在大规模设定下运行;以及对不同RNN变体(如LSTM、GRU及Transformer encoder-decoder等)的适应性抽取方法。
此外,评估指标也需要更加多元,除了保真度与准确率外,应衡量自动机的解释力、可验证性以及与原模型在关键决策边界上的一致性。对于希望在工程中尝试自动机抽取的从业者,建议从简单问题入手验证流程,先在可解释的合成语言上熟悉聚类、采样与自动机最小化等步骤,然后逐步迁移到更复杂数据。注意控制训练随机性、确保样本覆盖并结合多种聚类与验证手段以获得稳健结果。将抽取得到的自动机视为诊断工具而非绝对真理:它们能揭示RNN中的典型行为模式,但可能遗漏由连续表示承载的细微信息。总体而言,从循环神经网络中抽取自动机是一条将神经与符号方法连接的有前景路径。2018年的研究为这一方向奠定了技术基石,既展示了可行性也指出了现实中的限制。
随着表示学习、可解释性研究与形式验证技术的进步,自动机抽取有望成为构建可解释、可验证和可部署序列模型的重要手段。未来研究若能在抽取稳定性、自动化和可扩展性上取得突破,自动机方法或将成为深度序列模型工程实践中不可或缺的工具。 。