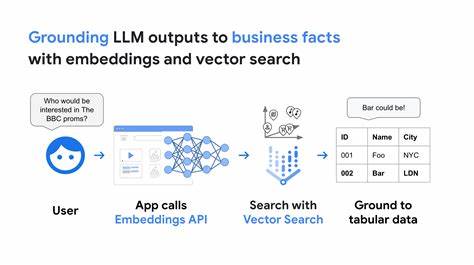
随着人工智能与自然语言处理技术的快速发展,大型语言模型(LLMs)在各类任务中展现出强大的语言理解与生成能力。然而,LLMs本身存在的知识时效性与准确性问题,尤其在涉及事实性信息时,容易产生“幻觉”或信息错误。为了突破这一瓶颈,WQ42项目提供了一种创新的路径,通过工具调用技术,将LLMs与维基数据这样庞大且结构化的知识图谱(KGs)深度结合,从而实现了基于实时、权威事实的智能问答与推理。维基数据作为世界范围内最重要的知识图谱之一,拥有海量不断更新的结构化事实资源,是支持精准知识推理的理想数据库。WQ42项目围绕如何让LLMs从纯语言生成转变为工具驱动的事实依据生成展开,探索了融合文本化知识图谱、工具调用与代码执行的全新范式。知识图谱以节点和边的形式存储事实关联,传统上LLMs一般依赖预训练数据或向量检索方法接入KG信息,存在一定的延时和维护成本。
而WQ42通过“工具调用”让LLMs主动调用以维基数据实体ID(QID)为核心的接口,实时抓取JSON格式的详尽项目信息。随后,利用专门的文本化方法将复杂的图形结构转为语言模型友好的Markdown格式,确保信息条理清晰且逻辑分组合理,进一步提升LLM对事实的理解和利用效果。这一创新不仅避免了以往向量数据库的依赖,还突破了知识陈旧和模糊搜索的限制,保证了回答基于最新权威的数据。WQ42定义了一套工具接口,包括根据自然语言标题搜索QID、获取对应QID的完整事实信息,及执行自定义Lua脚本实现复杂数学与逻辑推理的工具。利用这一工具集,LLMs能够在面对多实体、多跳推理、精确计算时,分步调用API并动态执行事实和计算任务。例如,在比较尼罗河与亚马逊河长度问题时,LLM首先调用工具获取两条河流的QID,再分别获取详尽事实信息,最后生成Lua代码完成长度对比分析。
通过集成Lua脚本执行,WQ42有效弥补了语言模型本身在数学运算和复杂逻辑推理上的不足,使结果更加精确可信。与传统大模型直接内嵌或微调知识图谱的方法相比,WQ42避免了繁重的模型训练与向量维护成本,实现了模块化、高效且可扩展的知识调用机制。在用户体验方面,WQ42融合了丰富的媒体元素支持,如图片、音频和视频,且回答始终标注维基数据QID链接,保证事实溯源的透明性和严谨性。该系统还能智能处理多语言实体识别与对应信息抓取,提升全球用户的问答体验。同时,针对缺乏数据或超出维基数据范围的问题,WQ42能诚实表达“不知道”,并鼓励用户参与维基数据的补充完善,保持知识库的活力。项目开源,基于Rust语言实现,体现了对高性能和安全性的重视。
WQ42的创意实现引发了对未来知识融合架构的深刻思考。他不仅仅是工具调用技术的展示,更是知识图谱和语言模型深度协作的示范,彰显了通过动态事实驱动辅助推理的新趋势。尽管当前仍存在多跳复杂查询和非结构化知识集成的挑战,但WQ42为研究者和开发者提供了宝贵的参考,表明无需庞大向量数据库和复杂微调,也能打造灵活且精准的知识问答系统。未来,结合维基功能函数(Wikifunctions)等动态函数库,并拓展对更多语言及模糊信息检索API的支持,WQ42框架有望迈向更强的智能化和普适性应用。总之,WQ42突破了单纯语言理解瓶颈,实现了语言模型与结构化事实数据库的高效联动,在提升问答准确性、事实根植性方面树立了新标杆,为自然语言问答、智能助手乃至知识管理系统的发展带来深远影响,也为大语言模型如何借力外部资源提供了极具前瞻的设计思路。不断演进的维基数据与工具调用技术将推动智能系统不断接近真实世界的复杂知识结构,赋能各行业用户获得即用即准的知识服务,开启更具信赖感的信息交互新时代。
。