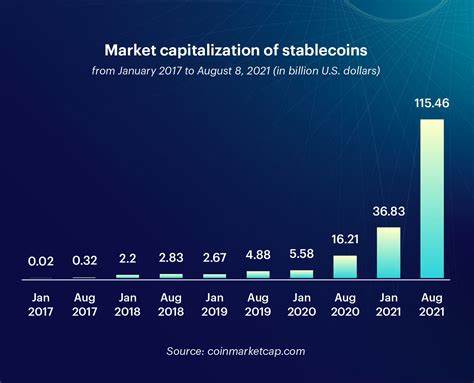
近年来,人工智能的发展使得科技巨头不断寻求更丰富、更专业的数据源,以提升AI系统的智能水平和用户体验。Meta作为社交媒体领域的领头羊,长期以来主要依靠公开上传至Facebook和Instagram平台的照片与视频,来训练其生成式和识别类人工智能模型。如今,Meta宣布将尝试接触并利用用户私人、尚未公开的照片数据,这一决定标志着AI训练数据的获取方式进入了一个全新的阶段。公开照片一直是社交媒体平台中最容易获取且大规模的数据形式,但这类数据明显存在一定的局限性。隐私设置让许多用户的内容只对特定群体可见,甚至很多拍摄的照片甚至未经上传就直接存储在手机相册或云端,未对外公开。随着技术需求的升级,这部分未公开的照片数据潜力巨大,可为AI系统提供更全面、更贴近生活的视觉信息,提升算法的准确性和智能化水平。
Meta近期推出的“云端处理”功能,允许用户主动授权平台定期上传其手机相册中的照片。借助这项功能,AI可以分析照片中的面部特征、场景内容、拍摄时间等信息,从而生成个性化的内容推荐,如照片拼贴、纪念回顾或AI风格重塑。尽管Meta对外宣称当前阶段并未使用这些未公开的照片直接进行训练,但这种数据的储存和处理本质上为未来将其纳入AI训练流程埋下了伏笔。对于用户而言,该功能既带来了便利,也引发了极大的隐私忧虑。允许平台访问私人照片意味着用户需放弃部分对个人数据的控制权。数据安全性、使用透明度以及用户授权的范围成为舆论关注的焦点。
许多隐私保护组织警示,未充分告知用户数据使用细节和潜在风险,是侵犯用户知情权和选择权的表现。回顾Meta过去的AI训练数据使用情况,有数据显示,平台早已秘密通过用户上传的公开内容来“采集”训练数据。Meta虽表示只使用满18岁成年用户上传的公开内容,但该界定标准的具体含义及执行力度未被完全公开,给外界监督留下了隐患。此外,技术的快速迭代也加大了隐私保护的难度。AI模型通过深度学习不断自我完善,甚至通过某些数据生成无法溯源的内容,一旦私人照片被纳入训练集,未来可能产生的伦理问题和法律风险就更加难以预估。面对这一充满潜力且挑战重重的环境,监管机构已开始着手制定相关法律法规,旨在保护用户隐私权利,限制科技公司不当利用私人数据。
欧盟的通用数据保护条例(GDPR)等条例在全球范围内树立了隐私保护标杆,未来或将推动Meta及其他巨头在数据使用上更加透明、规范。与此同时,用户自身也应增强个人信息保护意识。了解并审慎阅读各类服务条款,合理使用隐私设置,避免盲目授权APP访问敏感数据,是保障个人数据安全的基础。对于科技公司而言,如何在尊重用户隐私的前提下充分发挥AI潜力,构建透明、公正的使用机制,将是赢得公众信任的关键。技术角度看,AI利用私人未公开照片训练模型,能够极大提升算法对复杂场景和多样人群的识别能力,增强其生成内容的丰富度和个性化。这将带来更智能、更贴合用户需求的产品体验,如更精准的人脸识别、场景理解、智能相册管理等。
然而,技术进步不能以牺牲用户隐私为代价。透明的数据策略、明确的用户授权流程、完善的数据安全保障措施,是推动这项技术健康发展的基石。展望未来,随着AI与生活的深度融合,数据来源的界限将日益模糊。科技企业需平衡创新和伦理,公众和监管机构也将扮演重要监督角色,共同塑造一个既智能便捷又安全隐私的数字时代。总之,Meta开启利用私人未公开照片助力AI训练的尝试,无疑是人工智能发展史上的重要里程碑。它代表了技术进步的巨大潜力,也敲响了信息时代隐私保护的警钟。
正确引导这一趋势,将决定未来数字生态的走向和人类与技术共生的美好前景。