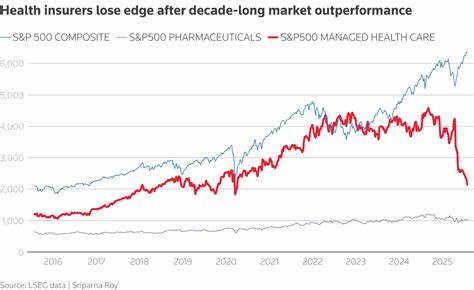
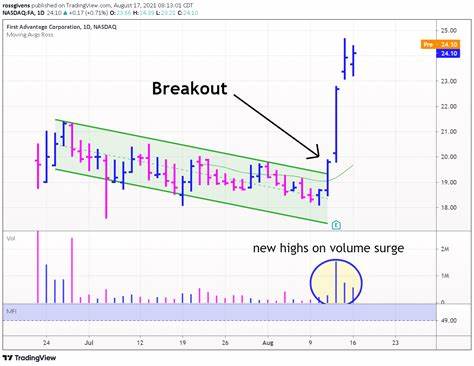
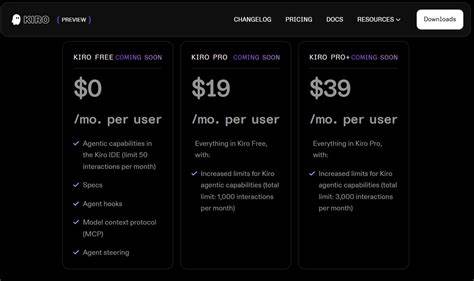
在现代软件开发过程中,调试工具和技术的数据格式对开发者来说至关重要。堆栈跟踪格式作为调试信息的核心载体,直接影响错误诊断的效率和准确度。SFrame堆栈跟踪格式作为一种特定且高效的堆栈信息表示方式,近年来逐渐受到关注,其简洁而富有结构性的格式设计为开发者提供了极大的便利。本文将深入剖析SFrame堆栈跟踪格式的结构、作用及实际应用,旨在帮助读者更好地理解和使用这一格式,提升软件调试和维护能力。首先需要明确什么是堆栈跟踪。堆栈跟踪通常指在程序出现异常或错误时,系统自动生成的一段调用堆栈信息,它记录了程序执行过程中的函数调用路径。
开发者通过分析堆栈跟踪,可以快速定位错误代码的位置,理解错误发生时的上下文环境。传统的堆栈跟踪往往格式多样、信息冗余或难以直观解读,SFrame堆栈跟踪格式针对这些问题进行了改进。SFrame堆栈跟踪格式属于结构化的调试信息,它以模块化和规范化为核心,通过统一的数据表示方式,提升堆栈信息的解析效率。该格式通常包括函数名称、源代码文件路径、代码行号以及调用参数等关键字段,确保每一条堆栈信息的精确性和可追溯性。SFrame格式的设计理念在于简化堆栈信息的阅读流程,减少不必要的冗余数据,便利错误定位的准确性。相比于传统的堆栈格式,SFrame支持更为清晰和层次分明的调用链展示,便于开发者通过直观的结构找到问题根源。
其模块化结构还方便工具进行自动解析和可视化显示,增强了调试过程的交互体验。应用SFrame堆栈跟踪格式的典型场景主要集中在复杂应用的错误诊断和性能优化中。例如大型后端服务或嵌入式系统中,错误日志异常冗长且难以梳理,SFrame格式通过结构化输出,降低信息复杂度,帮助团队快速定位异常函数和代码片段,从而缩短故障恢复时间。此外,SFrame格式具有良好的兼容性,可与多种调试器和日志分析工具结合使用,形成高效的自动化调试流水线。解析SFrame堆栈跟踪格式需要掌握其固定的字段顺序和编码规则。一般而言,每条堆栈信息包含函数调用名称、所在源代码文件及行号,时间戳以及调用线程信息。
某些实现还会添加调用参数的类型和数值,以便进一步复现场景。一般调试工具会提供对应的解析接口,将原始SFrame堆栈数据转换成易于阅读的日志格式,支持文本或图形界面展示。此外,一些开源库和插件还允许开发者自定义解析规则,满足特殊场景下的数据处理需求。优化SFrame堆栈跟踪的使用效果,关键在于选择合适的生成策略和展示形式。在生成策略上,应避免过度记录无关调用,控制堆栈深度和采样率,保证日志的代表性和简洁性。在呈现方面,结合可视化工具可显著提升分析体验,例如层级折叠、函数调用时间统计和异常标注,使开发者能够快速识别热点函数和潜在瓶颈。
在软件工程流程中,将SFrame堆栈跟踪格式作为标准错误日志格式,可以实现跨团队信息共享和自动化问题追踪。通过统一格式,测试人员、运维工程师与开发者能够更高效地协同工作,推动持续集成和持续交付实践。更进一步,结合人工智能与大数据分析技术,对大量SFrame堆栈数据进行模式识别和异常检测,有助于提前发现潜在故障,提高系统稳定性和用户体验。尽管SFrame堆栈跟踪格式具有诸多优势,但在推广应用时也面临一定挑战。不同编程语言和运行时环境对堆栈信息的生成机制存在差异,因此统一的格式标准需充分兼顾多样性和可扩展性。与此同时,开发者对调试日志的隐私与安全性要求日益提升,需要在SFrame格式设计中合理保护敏感信息,防止泄露风险。
未来,随着软件复杂度持续提高,调试工具和堆栈跟踪格式也将不断演进。预计SFrame堆栈跟踪格式将融合更多智能化特征,如错误诊断建议、代码变更关联及自动定位修复建议,进一步提升开发效率和软件质量。同时,结合云原生及分布式架构特点,支持跨节点、跨服务的统一堆栈跟踪定位,将成为重要的发展方向。总体来看,SFrame堆栈跟踪格式为软件调试和故障分析提供了清晰有效的解决方案,是推动现代软件开发流程优化的重要工具。深入理解其设计思想和使用方法,将极大助力开发者提升问题排查效率,缩短修复周期,保障系统稳定运行。掌握并善用这一格式,将成为每一位软件工程师提升自身技术实力和团队协作水平的关键所在。
。