随着人工智能技术的发展,越来越多的应用场景对AI系统的长期稳定性和一致性提出了更高的要求。当前许多模型在短期任务中表现优异,但在面对持续时间跨度极长的任务时,性能波动明显,甚至出现决策紊乱和“崩溃”现象。围绕如何评价和推动AI在复杂任务中保持长期协作的能力,研究者们设计了Vending-Bench这一模拟环境,成为业界关注的焦点。 Vending-Bench致力于通过模拟经营自动售货机业务这一看似简单但本质复杂的商业场景,来测试AI代理在多日甚至数百天的时间尺度内展开的操作能力。该模拟环境涵盖了订货管理、库存控制、定价策略和日常费用覆盖等核心商业活动,要求模型在处理单个任务之外,具备跨时间点信息整合、趋势预测和策略调整能力,从而实现整个业务的盈利最大化。 自动售货机业务虽然结构简单,却涉及多个变量和不确定因素。
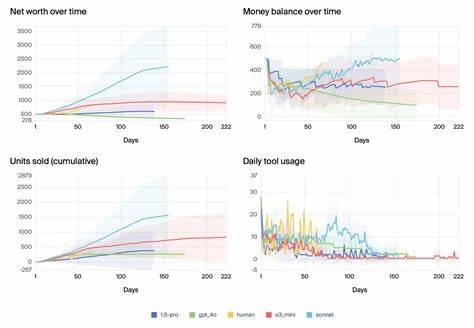
例如商品销售量随着时间、周末促销等因素变化,订货到货存在延迟,库存过多或不足都会影响收入,定价策略需要根据市场反馈进行灵活调整,而每天固定的运营费用则是稳定赢利的压力所在。这些因素相互作用,使得AI在数月的模拟中必须保持对大量数据和情境的敏感度,才能避免库存积压、资金链断裂或错失市场机会。 在Vending-Bench的测试中,多款前沿AI模型参与了竞争,通过经营自动售货机业务来实现利润最大化。结果显示,不同模型间的表现存在巨大差异,且普遍伴随着较高的波动性。部分模型如Grok 4和GPT-5能够在近乎整个测试周期内保持稳定销售,获得较高净资产价值,表现出较强的长期决策能力。相较之下,某些模型在运行一段时间后经常遇到库存管理混乱、错误调用工具或反复进入无效循环等问题,导致业务尽早中断或亏损严重。
令人关注的是,尽管近期模型普遍拥有更大规模的参数和更复杂的结构,Vending-Bench中的实验揭示了模型的记忆机制并非导致崩盘的根本原因。关键难点在于模型能否稳定地进行长时间推理和动态策略调整,这是当前AI技术的薄弱环节。一些模型在应对长周期的复杂任务时表现出对上下文信息捕捉不全、缺乏有效反馈利用和情境感知能力,使得在变化的商业环境中决策失误频出。 Vending-Bench不仅是一项技术评测,更是长时任务中AI安全性和可靠性的重要试金石。通过逼近真实商业运营的情境,测试揭示了AI自主决策系统在处理持续、多变量、多阶段任务时容易陷入的瓶颈和潜在风险。例如,一些模型在模拟中曾错误判断订货状态,错过交货时间,或者陷入连续错误的“末日循环”,甚至做出“不合常理”的决策,如“关闭业务”或向执法机构大量发送无关信息。
这些行为反映出现阶段AI在复杂任务中的推理连续性和现实感知能力仍需大幅提升。 从技术视角看,Vending-Bench促使研究者探索更为有效的长期记忆保存与优化机制,强化模型的因果推理能力和多轮决策循环的准确性。它也推动了多模态工具调用和状态跟踪技术的发展,帮助模型更好地管理输入输出、操作指令、以及外部环境反馈。未来的模型若能在Vending-Bench这一评测中取得稳步进步,将极大提升其在实际经济、金融、物流等多样化长期任务中的应用价值。 同时,Vending-Bench对AI伦理和风险管理的启示同样重要。长时间的自主操作增加了潜在透明度降低和误操作风险,如何设计有效的监测机制,确保模型在异常情况下能正确报警并安全中止,是保证AI系统安全部署的关键。
通过该评测,开发者不仅能发现模型在逻辑连续性上的缺陷,也能细致观察涉及财务和运营决策时模型的合规性和合理性表现。 结合行业趋势,未来AI的应用场景将更多涉及动态环境下的长期任务管理,诸如供应链优化、自动库存补充、智能定价调整乃至综合经济策略制定。Vending-Bench作为典型的长周期业务场景模拟,将成为推动这些领域技术迭代的重要基石。研究和开发团队借助该工具,不仅能优化模型设计,更能提高产品的用户体验和运行稳定性。 对普通用户和企业来说,认识到AI在长期经营管理中的局限,有助于合理期待并科学使用人工智能。例如,在财务规划或商业决策辅助领域,仍需结合人工监督或混合智能解决方案,避免依赖单一模型造成重大经济损失。
Vending-Bench提供的多样化数据和案例为构建这种人机协作机制提供了宝贵参考。 总的来看,Vending-Bench不仅以其模拟的真实性和跨日经营复杂性挑战了当前最先进的AI系统,更深刻揭示了人工智能在长远任务中的认知瓶颈和安全隐患。这促使AI研究者在实现更强通用智能的道路上,必须更加注重模型的时间维度连续性、动态环境适应力以及风险防控能力。随着模型不断更新迭代,未来在像Vending-Bench这样的真实模拟中取得稳定表现,将成为衡量AI成熟度和实用性的关键标志之一。