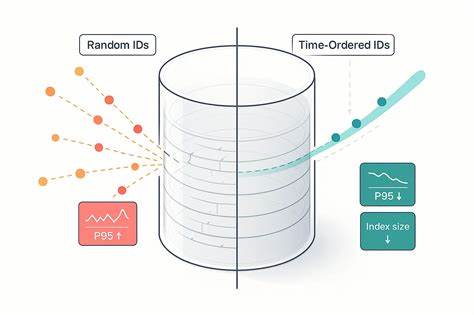
在现代数据库和分布式系统设计中,标识符的选择至关重要。一个高效、可靠且安全的标识符不仅能保证数据唯一性,还能提升系统的性能和可扩展性。UUIDv7,作为UUID族群中最新且被广泛关注的版本,凭借其独特的设计理念和技术优势,正在迅速成为开发者和数据库管理员首选的标识符类型。许多人对UUIDv7的认识仍停留在传统UUID版本的基本功能上,殊不知它在架构和性能方面带来了诸多令人惊喜的创新。UUIDv7的灵感来源于ULID(Universally Unique Lexicographically Sortable Identifier),两者均为128位长度的标识符,采用时间戳放置于标识符的左边,随机部分置于右边。这样的设计不仅保证了标识符的唯一性,还实现了时间上的有序性,非常适合需要按照时间顺序查询的数据场景。
相较于UUIDv4完全的随机生成方式,UUIDv7的时间顺序排列大幅优化了数据库的索引效率和数据检索性能。在分布式系统中,这种有序性尤其重要,因为它避免了因标识符乱序生成带来的写入性能瓶颈。RFC 9562对UUIDv7的规范提出了严格要求,其中最核心的是必须使用密码学安全的伪随机数生成器(CSPRNG)来保证随机部分的安全性和不可预测性。值得注意的是,不同的UUIDv7实现会在一些细节上有所差异,比如在同一毫秒内生成多个标识符时如何保证单调递增性。一些实现采用随机初始化计数器,另一些则基于时间戳的计数方案,或者结合两者以满足高并发环境下的顺序需求。即使在系统时钟回拨的极端情况下,部分实现还利用互斥锁或增加更细粒度的时间段,来确保生成标识符的严格单调递增。
这些设计并非简单的技术折衷,而是确保数据库分页查询、日志检索以及时间序列数据处理更加高效和准确的重要手段。虽然UUIDv7包含可提取的时间戳字段,但现实应用中不推荐直接利用这个时间戳进行业务逻辑处理,而更建议使用独立的时间戳字段。原因在于UUIDv7时间戳受具体实现细节和系统时钟调整的影响,有时可能不够精准或直接可靠。然而,UUIDv7的整体设计使其非常适合用作分区键,帮助数据库系统根据时间维度高效分区和管理数据。UUIDv7的应用还支持对时间戳部分进行灵活调整,例如在某些数据库系统(如PostgreSQL和Percona Server for MySQL)中,允许对时间戳进行偏移处理。这不仅有效隐藏了数据的真实生成时间,提升安全性,还帮助减少了在多进程并发生成UUID时的锁竞争,提高了系统生成速度和稳定性。
UUIDv7采用了传统的"十六进制加连字符"的字符串格式,这种格式在各类系统中广泛兼容且易于使用。不过,标准并不限制也可以采用更紧凑且可读性更高的Crockford base32编码方式,这与ULID的表现形式一致,能有效节省存储空间和提高用户体验。在数据库存储方面,建议尽可能将UUIDv7以128位二进制格式保存,而非字符串形式。二进制存储不仅减少了约30%至40%的存储空间,还在查询和索引效率上表现更优。基于此,UUIDv7的设计兼顾了存储成本与性能需求,为大规模数据系统提供了极具竞争力的解决方案。相比传统的自增主键,UUIDv7不仅克服了生成和同步过程中可能产生的冲突风险,还为分布式系统的并行处理提供了坚实的支持。
其128位长度虽然比bigint长一倍,但在实际磁盘空间占用中差异较小,并通过消除中间表和复杂数据层带来了整体系统简化的优势。此外,使用UUIDv7还可以防止通过顺序ID的暴力破解,避免泄露数据库中记录的总量信息,并支持更灵活的全球搜索特性。这使得UUIDv7不仅提升了安全性,也使数据管理更加智能化。UUIDv7的兼容性良好,允许在已有的UUID或ULID使用场景中无缝替代,降低系统升级风险和复杂度。多元化的实现和日渐成熟的生态环境,使得开发者能够根据具体需求灵活选择适合自己项目的UUIDv7生成方案。综上所述,UUIDv7代表了标识符技术的一大飞跃。
其创新设计兼具时间顺序性、随机安全性和存储高效性,在保障数据唯一性的基础上大幅提升了性能和安全水平。对于追求稳定、高效、可扩展数据管理方案的应用场景而言,UUIDv7无疑是未来发展的明智选择。随着越来越多数据库和分布式系统拥抱这一新标准,它将成为引领数据标识符技术革新的重要力量,助力下一代信息系统的建设和升级。未来,随着相关标准的逐渐完善和工具链的优化,UUIDv7的应用范围必将更广泛,其价值也将被更多企业和开发者认可和发掘。 。