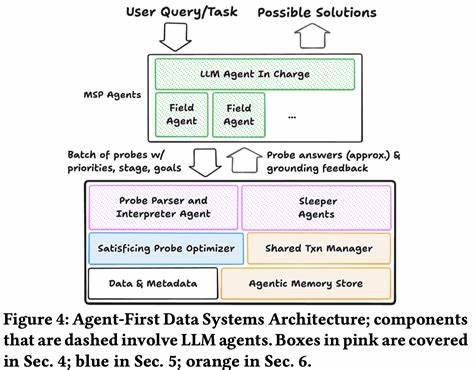
近年来,人工智能尤其是大型语言模型(LLM)的快速发展,已经深刻改变了我们与数据互动的方式。当下,越来越多的智能代理开始代理用户执行复杂的数据分析和处理任务,这种趋势不可逆转地推动着数据系统向智能化、自动化方向迈进。传统数据系统架构在面对此类智能代理驱动的高频探索和任务制定时,暴露出诸多性能瓶颈与设计不足。为适应未来数据处理需求,重新设计数据系统以支持Agent-First(以智能代理为核心)的架构理念,成为业内亟需解决的重要课题。 什么是Agent-First数据系统? Agent-First数据系统是指以智能代理为核心使用主体,设计和优化的数据存储与处理框架。与传统由人类直接驱动查询相比,智能代理具备高度自动化和主动推理的能力,能够根据上下文连续进行猜测、试验和优化 - - 这个过程被称为agentic speculation(智能代理性推测)。
数据系统如果能够理解并配合这种推测特性,在效率、响应速度和资源利用等方面将获得质的飞跃。 智能代理推测的四大关键特征 规模性:智能代理在处理任务时,可能产生海量并发的多轮查询,这种规模远超传统交互模式。数据系统必须具备高吞吐量的查询处理能力,以满足数以万计的任务并行需求。 异构性:代理在不同环境、不同任务下生成风格迥异的查询请求,有的数据涉及文本分析,有的则侧重图像处理或多模态数据融合,数据系统需要支持多样化的数据类型和访问模式。 冗余性:由于智能代理优化策略不定,会反复尝试多条查询路径,导致大量冗余查询。传统系统若无针对性优化,将浪费大量算力和存储资源。
可引导性:智能代理具有灵活的推理能力,数据系统应提供可控的反馈机制,便于代理根据系统响应调整策略,实现动态优化。 Agent-First体系架构的核心目标 面对上述复杂特性,设计Agent-First数据系统的首要目标是提升智能代理的整体效率和交互体验。通过优化数据查询接口、改进查询计划生成与执行、增强存储管理的智能感知能力,打造一套适应高度动态智能代理环境的数据处理平台。 重新定义数据查询接口 在传统系统中,查询接口主要面向人类用户,习惯基于静态上下文发起明确请求。而Agent-First系统需要设计支持连续交互、自动推测的接口。代理在实际使用中会反复探索数据,这种接口需要具备多轮上下文存储、动态参数调整和模糊查询的能力,助力智能代理高效实现复杂任务。
智能代理优化的查询处理策略 Agent-First环境下的查询处理需要对冗余查询进行识别和合并,避免不必要的重复计算。此外,系统应支持查询结果的快速缓存与共享,让多个相似任务复用已有计算,提高整体性能。针对异构数据,查询优化器需更加灵活,结合代理的反馈动态调整执行计划,比如选择不同的索引策略或分布式执行路径。 探索Agentic Memory Store的革新 智能代理在任务执行过程中,需要记忆此前的查询结果和推理路径,形成智能记忆库。Agentic Memory Store设计能够结合持久存储与快速缓存优势,实现对代理推测活动的高效存储管理。通过标准化存储接口和智能压缩算法,减少存储空间的占用,同时保证数据访问的低延迟,促进智能代理不断学习和优化。
数据系统的可扩展性与可管理性挑战 面向智能代理的数据系统不仅要满足性能需求,还需具备可扩展性和易管理性。随着代理数量和任务复杂度的飙升,数据平台必须能够灵活扩展计算和存储资源,同时保证系统的稳定性和安全性。优化分布式协调机制,支持动态负载均衡和故障自动恢复,是提升系统鲁棒性的关键所在。 AI驱动的数据系统未来展望 未来,Agent-First理念将助推数据系统朝着更加智能化方向演进。通过引入机器学习辅助的查询优化、语义理解和自适应资源调度,系统将更好地服务于智能代理的复杂需求,实现真正的人机协作新境界。此外,随着多模态数据和跨域知识集成的深入,Agent-First数据系统将在医疗、金融、制造等垂直行业发挥巨大作用,助力提升决策质量和业务创新能力。
结语 支持智能代理主导的数据系统架构,是推动未来数据生态升级的关键动力。通过理解和利用agentic speculation的固有特性,重新构建查询接口、优化查询流程、创新存储方案,我们能够开启一场数据系统的革命。拥抱Agent-First时代,将为企业和个人用户带来更智能、高效的服务体验,也为人工智能技术的持续进步奠定坚实的基础。随着技术的不断演进,未来的智能代理将不仅仅是工具,而是成为数据世界中不可或缺的"主宰",引领人类迈向全新的智能时代。 。