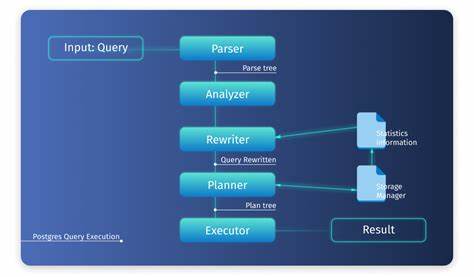
PostgreSQL作为开源数据库管理系统,以其强大的功能和优秀的性能优化机制在数据库领域占据重要地位。SQL作为一门声明式语言,用户仅需指定所需的数据结果,而具体的执行步骤由数据库管理系统内部的查询优化器决定。优化器通过评估多种可能的执行方案,选择最优的计划以实现高效查询。但在实际执行过程中,“预计”(expected)与“实际”(actual)的执行指标常常出现偏差,这种偏差不仅影响性能,也反映了优化器统计信息和成本模型的准确性。近年来,借助视觉化工具对PostgreSQL查询计划的“预计”与“实际”指标进行对比分析,成为研究和优化这一领域的重要手段。本文将从查询优化基础出发,深入探讨如何通过视觉化工具全面剖析PostgreSQL查询计划的执行表现,揭示其背后的优化逻辑与性能瓶颈。
SQL语句编写过程中,查询优化器面临着众多选择,例如采用索引扫描或全表扫描,选择合适的连接算法如哈希连接、嵌套循环等。不同计划的成本预估基于统计信息,但当数据分布、关联性或参数变化时,预计与实际性能可能产生显著差异。理解这些差异对于优化复杂查询、调优数据库参数以及开发自定义成本模型至关重要。本文介绍的Plan Explorer工具为此提供了强有力的支持。Plan Explorer允许用户设定二维参数空间,逐点执行SQL查询,收集查询计划和实际执行结果,通过图形化展示不同参数组合下的查询计划变迁、成本估计、执行时间及返回数据行数。其艺术化的视觉表现不仅美观,更直观反映了优化器决策的逻辑与误差。
核心原理是通过新浪潮影响参数,使查询条件动态变化,从而观察数据库在不同过滤程度下切换计划的阈值。举例来说,一个包含100000条记录的测试表,在条件范围变化时,PostgreSQL可能由顺序扫描转为索引扫描,或改变连接类型。Plan Explorer基于WebAssembly版本的PostgreSQL(PGlite),实现纯浏览器对查询计划的解析,满足无服务器环境下的快速实验需求。为突破JavaScript跨域限制以及支持真实数据库执行,该工具引入代理服务器模式,转发查询至真实PostgreSQL实例,从而获取更准确的实际执行数据。该架构既支持部署灵活,也方便集成自定义扩展和复杂数据集。在视觉输出方面,工具生成多种图像:包括查询计划分布、预计成本曲面、实际执行时间曲面、预计结果行数及实际返回行数热图,以及估计误差图。
通过这些图形,数据库管理员和开发者能清晰看到何时优化器切换执行策略,哪些参数组合导致计划剧变或执行性能波动。特别是预计与实际返回行数的差异,揭示了统计信息的失配,比如未捕捉的跨列依赖关系。通过引入PostgreSQL的extended statistics,可以提高估计准确度,进而优化查询计划选择。以一个自连接查询为例,该查询对参数空间的二维范围进行遍历,Plan Explorer发现了五种不同的执行计划,其中哈希连接组合顺序扫描与索引扫描的切换尤为显著。深入分析两种代表性计划,能观察到PostgreSQL对连接类型的优化,例如在左连接被过滤函数影响下,自动转换为内连接以避免无用元组生成。这种优化策略虽透明,却对性能提升影响巨大。
此外,预计成本与实际执行时间曲线虽大致一致,但后者更受环境波动、缓存状态和统计采样局限影响。实际执行时间图形明显存在散点现象,提示单次运行测量噪声。采用多轮采样、平均化策略将更可靠地指导优化决策。查询返回结果的估计误差则直接反映了优化器对数据分布模型的局限。常规估计函数在面对跨列选择性时存在较大偏差,误差图的艺术化视觉实际上是优化过程中的“副产品”,为调模型者提供直观反馈。Plan Explorer的开放源码策略促进了社区对数据库内部机制的深入理解与模型改进。
此外,其服务器代理模式为分析大规模数据集和定制扩展提供了有力支持,拓展了传统纯客户端工具的适用场景。总结而言,PostgreSQL的查询优化是复杂而精妙的艺术,预计与实际执行指标之间的视觉对比为我们展现了优化器决策的全过程。凭借Plan Explorer这类工具,数据库开发者与管理员能够更直观、更系统地理解并调优查询性能。未来,通过结合更丰富的统计信息、执行环境监控以及机器学习方法,有望进一步提升查询计划的准确性与执行效率。随着数据规模的不断增长和应用复杂性的提升,基于视觉化的查询分析将成为数据库优化不可或缺的利器。