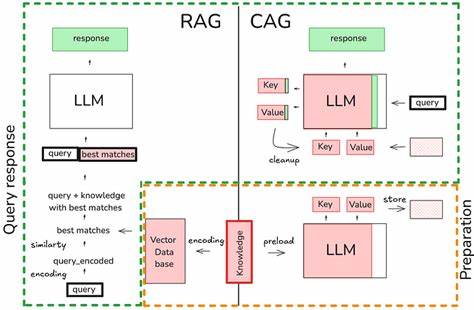
在人工智能和自然语言处理领域,检索增强生成(Retrieval-Augmented Generation,简称RAG)模型凭借结合检索和生成能力的优势,成为提升问答系统、对话系统和知识驱动模型表现的重要技术。然而,随着模型规模扩大和推理长度变长,如何有效提升推理速度成为业界关注的焦点。传统大规模语言模型的Key-Value(KV)缓存只能有效复用前缀上下文信息,导致缓存利用率不足,影响推理效率。最近,LMCache提出了重用非前缀KV缓存的创新机制,在提升RAG性能方面实现了三倍加速,受到了广泛关注。LMCache的设计理念围绕最大化KV缓存复用展开,通过允许非连续上下文的缓存混合(KV Cache Blending),打破了传统框架中对连续上下文缓存依赖的限制。不同于传统的仅能重用连续前缀缓存模式,LMCache能灵活将多个缓存片段无缝融合,避免了重复计算和冗余推理过程,显著节约了计算资源和时间。
这一技术创新不仅优化了缓存管理机制,还结合了vLLM引擎的高速推理能力,使得整体推理过程更加高效。对于需要频繁进行知识检索和上下文拼接的RAG任务,LMCache的KV缓存混合技术带来了革命性的性能提升。项目中通过对比两套环境,一套使用传统vLLM实例,另一套启用LMCache与KV缓存混合,得出显著的时间节约效果。用户通过交互式界面动态选择与重排序文本片段构建上下文,实现了更加灵活和高效的推理流程。具体应用方面,LMCache适用于需要动态构建长上下文的对话与问答场景。系统支持多GPU运行环境,充分发挥硬件性能优势。
同时,结合Hugging Face的预训练模型,保障模型的开放性和可扩展性。部署流程简便,用户只需设置环境变量并启动对应服务即可快速体验速度提升。在实际测试当中,启用LMCache的环境相较传统服务在时间到首令牌(TTFT)上实现了超过三倍的速度提升,这意味着响应时间更短,大规模在线服务的并发能力和用户体验均大幅提升。LMCache的优势不仅体现在速度上,更在于它的灵活性。系统允许用户通过界面调整系统提示、上下文组合与生成参数,满足差异化业务需求。无论是面向企业的专用知识库构建,还是面向大众的智能问答助手,LMCache都能够有效降低推理开销,提升模型响应效率。
此外,该方案的开源代码结构清晰,包含前端用户界面和后端服务入口,便于社区贡献和二次开发。Docker容器化部署降低了环境依赖挑战,使得研发团队能快速复制和验证性能优势。与此同时,支持多卡并行运行,结合NVIDIA GPU硬件加速能力,使得在真实大规模负载环境中具备良好的扩展性。未来,随着大规模语言模型和多模态模型挑战的不断升级,如何更高效地管理KV缓存以及上下文拼接将更为关键。LMCache的技术思路为业界提供了宝贵经验,即通过缓存融合技术提升性能,以减少重复计算,同时保持生成多样性和准确性。结合目前RAG模型在知识图谱构建、定制问答系统、智能客服、内容生成等场景中的广泛应用,LMCache将在提升用户体验和资源利用率方面发挥核心作用。
综上所述,LMCache的非前缀KV缓存重用机制以其独特的缓存混合策略,实现了RAG模型推理效率的跨越式提升。这个技术不仅为大规模语言模型的高速推理开辟了新道路,也为相关应用场景的性能瓶颈提供了解决方案。未来,随着模型规模继续扩大和应用多样化,LMCache有望成为行业内提升推理速度与降低计算成本的重要利器。创新的缓存复用思想结合灵活的上下文动态构建,为智能对话和知识驱动生成系统注入了新的活力,推动NLP技术迈向更高效、更智能的时代。