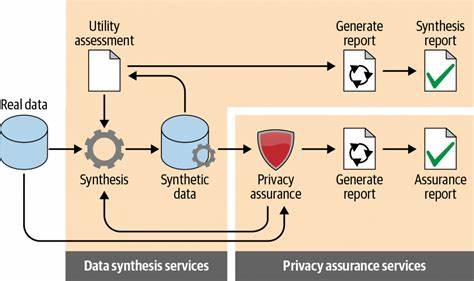
随着人工智能技术的飞速发展,数据的重要性愈发凸显。尤其是在机器学习和深度学习领域,大量高质量的数据成为模型训练的关键。然而,现实世界中获取充足且贴合需求的真实数据往往面临诸多限制,如隐私保护、数据敏感性、安全合规及成本高昂等问题。合成数据生成这一定制化制造数据的技术因此应运而生,成为解决数据瓶颈的有效方法之一。合成数据指的是通过模拟、建模或基于已有数据驱动的算法生成的伪造数据,其目的是在不曝光真实数据的情况下,巩固模型的性能和泛化能力。学术界对合成数据的研究由来已久,早在几十年前便有相关基于统计模拟和规则引擎的尝试。
但近年来,随着深度学习尤其是大语言模型(LLM)的兴起,合成数据生成技术焕发出新的活力和广泛的关注度,诸如Meta AI推出的Llama 3 Herd研究、TinyZero和Sky-T1等公司的应用案例,为合成数据的产业化提供了参考。尽管学术论文和开源工具层出不穷,但一线实际生产环境中,合成数据生成的落地应用仍然不多见,有观点认为其多停留在试验和研究阶段。究竟合成数据技术在真实产品环境中有多实用?在哪些领域发挥着真正价值?现实世界的故事和经验值得深入关注。合成数据的实际应用场景主要包括以下几个方面。首先是在缺乏足够真实数据的情况下,为机器学习模型提供补充训练样本。许多企业在面对冷启动阶段,或者某些特定业务场景的数据稀缺,利用合成数据生成Q&A对、图像、音频甚至复杂的多模态数据,以提升小型模型的性能与泛化能力。
其次,合成数据在保护隐私和遵守合规方面表现突出。以医疗、金融为代表的高敏感性数据领域,使用合成数据模拟真实世界数据特征,不仅保障了用户隐私安全,也使得模型训练与测试流程能在法律框架内顺利进行。第三,合成数据方便加速产品测试和评估。实际产品开发过程中,数据往往分布不均或包含异常,通过生成平衡、结构多样的合成数据为系统调优提供了便利。此外,针对时间序列、传感器数据、天气气候预测等场景,长期以来合成数据方法就被应用于建模和仿真。合成数据的优势不仅限于低成本与数据隐私,它还能够灵活实现多样化场景模拟、罕见事件强化训练以及数据增强,从而提升机器智能系统的鲁棒性。
然而,合成数据生成依然面临不少挑战。数据质量和真实性是核心难题。合成数据若过于理想化、与实际环境差异较大,将导致模型过拟合合成特征,无法在真实场景中有效应用。以医疗或工业领域的时序信号数据为例,单纯基于已有统计规则混入噪声的合成方法难以覆盖复杂的现场环境变异。大型语言模型在生成合成问答或推理路径时,虽然表现出强大的表达能力,但对信息的准确性和逻辑严密性仍有局限,尤其是多个推理步骤串联的复杂任务中容易产生“幻觉”效应。模型训练与评估方面,对合成数据质量的量化评价体系尚不完善,如何设计科学合理的指标来判断其真实性和有效性,是业内关注的重点。
与此同时,企业在实施合成数据流程时需要面临工程复杂性、算力需求以及数据治理的多重考验。此外,合成数据的伦理问题也逐渐显现。合成内容是否透明、可溯源?在模型决策过程中,合成数据的贡献与风险如何分配?这些问题亟需产业界与监管层共同规范。真实世界的应用案例为合成数据技术的前景带来启示。某些文档解析引擎充分利用大型模型生成的数据对其小型模型进行微调,实现了延迟从秒级到亚秒级的显著提升,适应了时效严格的业务需求。冷启动推荐系统也利用合成用户行为模拟数据,有效缓解了启动阶段样本不足带来的预测能力不足。
尽管如此,许多领域仍处于探索期,大规模商业化应用尚未全面铺开。当前,开源工具和平台的兴起为企业提供了试水合成数据的基础设施,如Meta的synthetic-data-kit和Bespoke Labs的Curator。这些工具降低了技术门槛,使更多中小企业得以尝试基于合成数据的模型训练与优化。未来合成数据的发展趋势有望围绕以下几个方向推进。首先是合成年代数据和真实数据的深度融合,建立更强的混合训练体系。其次,提升合成数据生成模型的多模态协同能力,支持跨文本、图像、音频的综合模拟。
第三,发展精准的数据质量评估与校验工具,赋予用户更高的信心。第四,完善合成数据生成过程中的隐私保护与合规机制,确保技术边界清晰明确。值得注意的是,随着基础模型的成长,合成数据生成不再仅限于单纯数据仿真,更成为赋能模型推理能力和任务表现的关键纽带。总结来看,合成数据生成作为一种突破传统数据限制的技术,正在逐步从学术研究走向工业应用,但其成熟度和普适性尚未达到理想水平。现实世界中的应用多依赖于特定场景和任务需求,且需要结合真实数据的验证与反复迭代。在未来,随着技术演进与产业生态完善,合成数据有望成为提升人工智能模型训练效率、保护隐私安全、应对复杂多样应用挑战的重要工具。
对于业界从业者而言,理解合成数据的优势与局限性,合理规划数据生成与使用策略,方能在技术红利中把握住机遇,推动人工智能的健康持续发展。