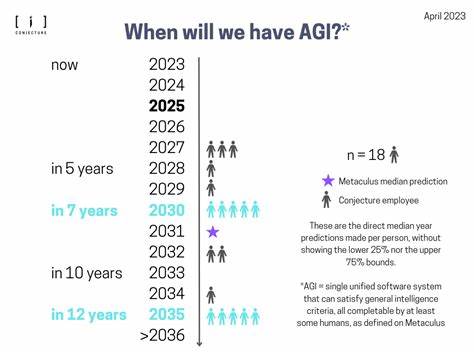
在C++编程中,拷贝构造函数是类设计中的重要组成部分,影响对象的生命周期管理与数据传递安全。当开发者定义一个类时,往往期望拷贝构造函数能够准确反映类的拷贝能力,方便编译器在编译阶段进行正确的类型推断和优化。然而,现实中我们经常遇到一种困惑:编译器认定某个类是可拷贝构造的,但实际上却无法成功进行拷贝操作,导致编译错误。为什么会出现这样看似自相矛盾的情况?要理解这个问题,必须深入剖析C++编译器判断类型特性的机制及语言标准中的相关规则。 首先,拷贝构造函数的定义和判断依据是C++标准库类型特征(如std::is_copy_constructible)的核心。标准库通过检测类的拷贝构造函数声明是否存在且未被显式删除,来决定该类是否可拷贝构造。
这意味着只要类中声明了一个非删除的拷贝构造函数,类型特征便会报告该类是可拷贝构造的,即使函数体可能无法被实际实例化。 举个常见的例子,假设有一个模板基类Base,显式删除了它的拷贝构造函数,而派生类Derived继承自Base并自定义了一个拷贝构造函数。在Derived的拷贝构造函数中,如果尝试调用Base的拷贝构造函数进行基类部分的复制,由于Base的拷贝构造被删除,编译时会报错。然而,由于Derived中确实存在一个未被删除的拷贝构造函数声明,类型特征仍然认为Derived是可拷贝构造的。 这是一个重要的区分点。类型特征检测的是“声明层面”的信息,即判断该类型是否具备非删除的拷贝构造函数声明,但不会尝试实例化函数体或检查实际实现中的错误。
这样的设计背后有合理的原因:如果类型特征强制要求函数体可正确实例化,代码的组织方式将受到极大限制,比如需要将所有函数定义暴露在头文件中,而这往往违反模块化编程和实现隐藏的原则。 因此,C++标准设计上的权衡决定了判断是否可拷贝构造主要依赖“存在性”和“删除状态”,而非“可实例化性”。这就导致编译器在某些情况下会给出“假阳性”的判断,即认为类是可拷贝构造的,但实际调用时发现不可用。 这种行为对于代码设计和调试带来了哪些影响?首先,开发者需要认识到自定义拷贝构造函数时,必须保证其实现逻辑正确,尤其是涉及基类或成员对象的复制操作。如果基类不可拷贝,那么Derived的拷贝构造函数必须采用适当策略处理基类——比如不调用基类拷贝构造函数而是采取其他手段初始化。否则,在尝试复制Derived对象时,将会遇到编译错误。
其次,合理使用默认拷贝构造函数也是关键。如果基类本身不可拷贝,那么在派生类中显式默认拷贝构造函数通常会被自动标记为删除,类型特征也会正确反映该类不可拷贝。换言之,在基类不可拷贝的场景下,使用显式默认拷贝构造函数可以避免声明存在但不可使用的尴尬情况。 此外,了解编译器在类型特性推断过程中的限定,对于利用现代C++特性实现模板元编程和SFINAE技术至关重要。错误理解类型是否可拷贝可能导致模板匹配错误、静态断言失败,或者运行时行为异常。开发者应结合实际编译器报错信息和类型特征检测结果,准确判断类设计的可拷贝性,并做出调整。
针对“为什么C++认为我的类可拷贝构造但不能”这一疑问,也存在若干解决思路。首先,可以将拷贝构造函数定义移出类内,放入源文件中实现。这样,类型特征根据声明判断可拷贝,但只有在实例化时才会触发报错,适合隐藏实现细节。其次,可以考虑将基类设计调整为可拷贝,或为派生类提供不同的拷贝语义,比如禁用拷贝而使用移动操作,或实现自定义的拷贝逻辑。也可以通过使用智能指针或容器来间接管理复制行为,避免直接涉及不可拷贝成员。 综合来看,C++判断类是否可拷贝构造的逻辑遵循语言设计原则和编译器实现细节的平衡。
类型特性的判定主要基于是否存在非删除的拷贝构造函数声明,而不依赖于其实现是否可实例化。这一机制允许编译器和程序员拥有更灵活的代码组织与设计空间,但也带来了误判的风险。理解这一原理可以帮助开发者写出更健壮的C++代码,减少拷贝相关的错误和调试难度。 拷贝构造函数在C++的对象模型和资源管理中扮演着至关重要的角色。通过深入理解其工作机制及编译器如何判断类型特性,程序员能够更好地驾驭语言的复杂特性,从而设计出高效、稳定且可维护的软件系统。未来随着C++标准的不断演进,相关特性和工具链支持可能进一步完善拷贝构造的检测机制,但当前阶段,透彻把握其底层原理仍是C++开发者必备的技能之一。
。