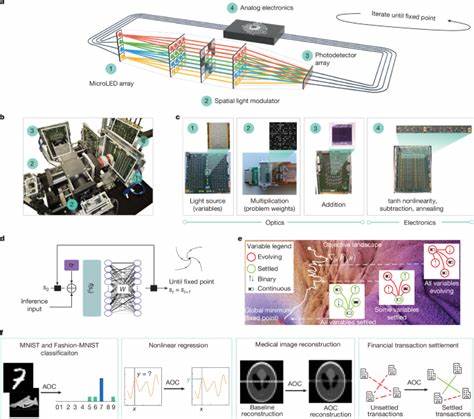
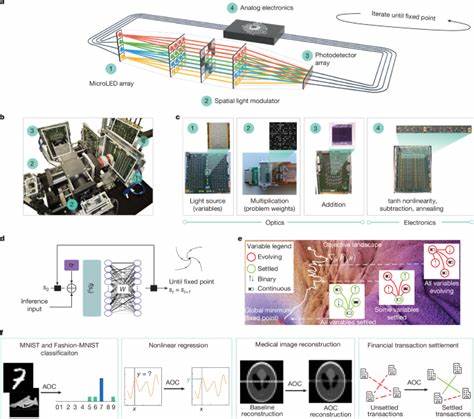
近年来,基于大规模语言模型的人工智能工具如ChatGPT迅速普及,成为研究者们获取信息和启发思路的得力助手。然而,伴随着其广泛应用,学术界也逐渐暴露出一些令人担忧的问题,其中最值得关注的是所谓的"维基百科脑"(Wikipedia Brain)现象。这种现象体现了ChatGPT在提供研究信息时虽能引用真实来源,却往往陷入一种浅薄而片面的认知,给研究带来了误导甚至错误的风险。 "维基百科脑"指的是ChatGPT倾向于依赖容易获取且广为人知的信息资源,如英文维基百科及其链接文本,无法深入挖掘非常规、非英语或较为专业的原始资料,最终导致研究结论片面且缺乏深度。表面上看,ChatGPT引用的文献和数据真实存在,回答条理清晰,却掩盖了事实上的不准确和不全面。恶劣之处在于它常以极强的自信心呈现答案,容易让使用者误以为其做了彻底且全面的调查,其实只是"懒惰"地抓取网络上流行且便捷的信息,忽略了对复杂问题应付出的细致推敲和批判性思考。
这背后的根本原因在于语言模型的训练机制及检索方法。ChatGPT主要基于大量公开文本语料进行语言预测与生成,依赖互联网搜索引擎检索相关内容时,也被算法选择所限制,更偏好权威度高但通俗浅显的资源。此模式在面对高度专业化或跨文化的历史、社会、经济等学科问题时显得力不从心。以德国殖民时期青岛的土地价值税政策为例,众多网络资源及英文论文常将其塑造成接近"单一税"模型,以符合流行的乔治主义叙事。然而深入检索德文原始档案和一手资料,结合权威历史学者的研究发现,实际情况更为复杂,政策在某些方面与乔治主义原则存在出入,部分叙述甚至属于夸大其词。令人遗憾的是,多版本ChatGPT在面对这一问题时均未能识别和引用这些深层资源,反而不断重复容易检索的片面结论。
此外,即使研究者主动提供了新发表的详尽分析文章,经过搜索引擎索引后,ChatGPT的输出也未明显改善,对新信息的摄取和整合十分有限,体现了其更新机制与训练数据的慢节奏及固化特点。GPT-5等较新版本虽然在一定程度提升了对非英语文献和复杂信息的处理能力,但仍存在对强关联权威研究的忽视,且引用机制偶尔出现疑似"拼凑式"的文献支持,令人对其信息源透明度和可靠性产生疑问。由此可见,依赖ChatGPT完成所谓"深度研究"存在本质风险。 研究人员应当认识到,虽然ChatGPT等人工智能工具在整理公开信息、生成简洁报告方面效率惊人,却绝非研究方法的替代品。传统的学术严谨性要求研究者必须亲自查阅原始档案、阅读多语言文献,以及评估不同资料间的一致性和潜在偏见。AI工具生成的报告若未经人类专家批判性审查,极易造成信息误导,降低研究质量,甚至助长错误知识的传播。
更重要的是,那些影响深远的理论观点及历史解释往往隐藏在边缘文献中,非主流语言写作的资料,或因翻译和传播障碍难以被简单检索。依赖机器生成的表层信息,形成的认知壁垒对学术发展极为不利。 为了应对"维基百科脑"的陷阱,研究者应采取多种措施提升研究深度和原创性。首先,应尽量获取并阅读非英语的原始资料,尤其是在涉及跨国、跨文化的历史社会议题时,不唯英语而视。其次,应培养对AI生成内容的批判意识,发现表面答案时,主动质疑其完整性与代表性。再次,可以主动向AI模型提供定向的深度提示,促使其检索更多元来源,包括一手档案和权威专著,避免被常见英文摘要所局限。
最后,也鼓励研究人员在网络平台公开发布高质量、经过充分验证的原创研究,增强搜索引擎和AI模型对准确知识的访问能力。提升数据可见度,推动AI更加智能地"学习"可靠信息,有助于逐步减少低质量浅薄回答的比例。与此同时,研究社区内部也应加强对AI在学术应用中的伦理规范与质量保障讨论,制定使用指南和监督机制,防止AI误导并提升其辅助手段的效力。 总体而言,ChatGPT和类似大语言模型为研究者提供了极大便利,但不可盲目依赖其输出,必须警惕"维基百科脑"的陷阱,强化对基础资料的自主调查与解读。保持学术探索的耐心与严谨,注重多元信息源与批判性思维,仍是实现学术创新和发现真理的关键路径。未来AI研究工具的发展,若能真正整合深层、权威且多语言资料,且透明展示信息来源的关联,或许能更好助力科研,但那一日尚未到来。
研究人员唯有牢记人工智能辅助的本质,继续发挥人类智力的独特优势,才能在知识的海洋中探寻到真实与深刻。 。