随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理领域的应用日益广泛,从文本生成、机器翻译到智能问答,LLM展现出强大的语言理解与生成能力。然而,支持这些复杂模型的硬件资源,尤其是显存容量(VRAM)成为制约性能发挥的关键因素。针对这一需求,VRAM计算器成为衡量和预测模型运行所需资源的利器,帮助开发者和企业更精准地掌握硬件配置要求,实现资源优化和成本控制。本文将深入探讨VRAM计算器的工作原理、重要参数以及如何利用其评估大型语言模型的可运行性。 大型语言模型的规模和复杂度不断提升,参数数量从数亿到上百亿乃至千亿级别,促使模型训练和推理阶段对计算资源提出了更高要求。显存容量直接影响模型的模型权重、激活函数和缓存的存储,尤其在推理过程中影响模型的响应速度和处理能力。
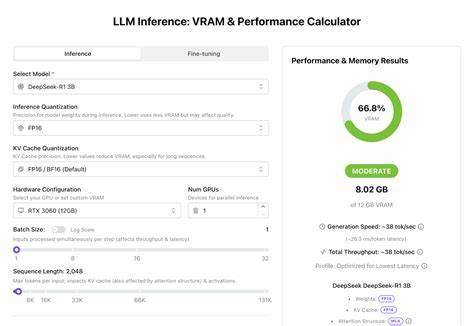
传统经验估算方法难以准确反映实际需求,VRAM计算器应运而生,为开发者提供基于模型架构、硬件配置和运行环境的动态计算工具。它综合考虑模型参数量、层数、隐藏维度,激活内存分配,量化精度,输入序列长度,批处理大小以及并发用户数等多维度因素,输出显存使用和性能预估数据,指导合理配置GPU及多卡并行策略。 选择精确的权重量化策略是影响VRAM消耗的关键因素之一。权重的精度越高,模型推理效果通常越稳定,但所需的存储空间也随之增大。FP16(16位浮点)权重因其在保持计算精度与内存占用间的平衡,成为推理阶段的主流选择,而FP32虽然精度更高但消耗显存更多。还有诸如8位或4位量化策略能够进一步降低显存占用,但可能伴随一定的精度损失。
VRAM计算器允许用户针对不同的量化精度自定义模型参数,实时反映显存需求变化,辅助选择最佳性能与内存利用率的组合方案。 KV缓存(键值缓存)是推理过程中尤为重要的组成部分,它保存历史上下文的中间信息,帮助模型在长序列输入下保持连贯的生成性能。KV缓存的量化同样对显存消耗产生明显影响,尤其当输入序列长度较长时,缓存所占内存甚至可能超过模型权重。通过降低KV缓存的量化位数,可以大幅减少显存压力,从而支持更长的上下文处理和更高的批处理量。VRAM计算器通过模拟不同KV缓存量化配置,助力开发者找到在功能和资源利用间的最佳平衡点。 硬件配置是VRAM计算器评估的基础,常见的GPU型号其显存大小、存取速度和带宽性能存在差异,对运行LLM的表现产生直接影响。
VRAM计算器内置多款流行GPU硬件参数,允许用户选择单卡或多卡并行推理模式。用户还可以自定义显存容量,以适应非主流硬件环境。并行计算在拯救显存瓶颈和提升推理吞吐量方面发挥巨大作用,合理设置设备数量及批处理大小,可以显著改善运行效率。通过参数调整和模型模拟,VRAM计算器为多场景多设备环境提供科学支撑,指导合理配置计算集群。 输入序列长度和批处理大小是影响显存需求和推理性能的两个重要维度。较长的输入序列使得模型需要缓存更多的上下文信息,相应地增加了KV缓存的显存占用,且激活函数计算复杂度提升,导致显存压力倍增。
与此同时,批处理大小(Batch Size)决定每个推理步骤并发处理的输入数量,较大的批量能够提升吞吐量,但也需要更多的GPU显存支持。VRAM计算器能够帮助用户根据具体应用场景和硬件限制,平衡输入长度与批处理大小之间的关系,以实现理想的内存占用和计算速度。 并发用户数是另一决定推理资源配置的关键因素,尤其是在面向互联网服务或多用户应用时。每个并发用户均占用一定的显存资源,随着同时在线用户数增加,显存需求以非线性方式增长。通过模拟不同并发用户数,VRAM计算器为系统规划提供量化依据,防止资源不足导致响应延迟或崩溃。此外,现代推理框架支持部分计算任务通过CPU、RAM甚至NVMe进行卸载,扩展了模型运行环境的灵活性。
VRAM计算器亦考虑这些卸载选项,反映不同硬件配置下的资源分配和性能变化,助力开发者做出更合理的部署选择。 模型架构的内在复杂度对显存需求产生深远影响。参数规模、层数、隐藏层维度、激活函数类型以及门控机制(如专家模型MoE)都会直接或间接影响内存占用和计算负载。大型混合专家模型(MoE)虽然提升性能和效率,但其模型计算路径复杂,KV缓存管理更为繁琐,往往导致显存消耗显著增加。VRAM计算器利用经过多次迭代优化的估算公式和架构分析模型,结合实时硬件性能参数,准确预测不同模型结构在各类显存环境下的表现,从而提升规划的科学性与精确度。 性能指标如生成速度(Tokens Per Second, TPS)和首次生成时间(Time to First Token, TFTT)是评判模型推理体验的核心标准。
显存不仅影响模型是否能完整加载运行,还关联着计算瓶颈和数据传输时间。VRAM计算器通过历史性能数据及现代推理优化算法,估计不同配置下的TPS和TFTT,帮助开发者直观评估模型响应效率。优化这些指标对于提升用户体验、缩短交互时延、降低运维成本尤为重要。依据计算器结果,团队可针对具体瓶颈进行软硬件调优,如调整量化策略、增加显存或启用更多GPU设备。 值得注意的是,VRAM计算器提供的计算结果虽然基于详尽的模型参数和硬件规格,但依旧带有一定的不确定性,受限于实际推理框架的实现细节和底层驱动优化水平。不同厂家和版本的软件堆栈,以及系统环境变化,都会对实际显存使用和性能产生影响。
因此,VRAM计算器更适合作为规划和对比工具,而非绝对标准。开发者在设计和部署实际应用时,还需配合真实环境测试进行调整,以确保稳定高效运行。 总结来看,VRAM计算器为大型语言模型推理提供了科学、灵活、可视化的资源评估手段。它帮助开发者基于模型参数、推理精度、硬件条件及使用场景量化显存需求,提供合理的配置建议与性能预估,推动LLM应用的高效落地。随着模型规模的不断扩大和硬件技术的日新月异,借助VRAM计算器等工具进行硬件资源规划和性能优化,已成为AI团队提升竞争力的必由之路。未来,随着推理框架和硬件的进一步创新,VRAM计算器也将不断迭代升级,为更大规模和更复杂模型的智能应用保驾护航。
。