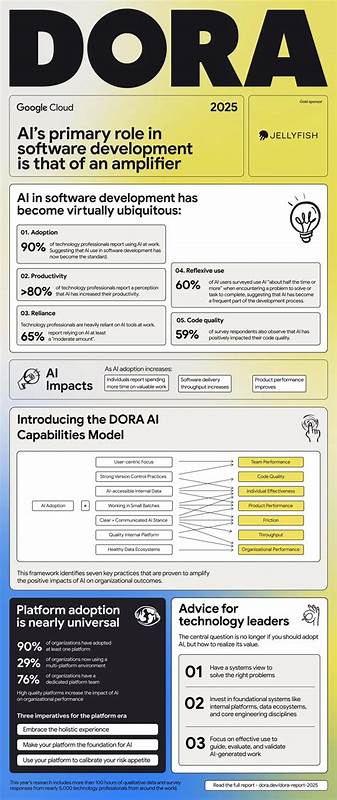
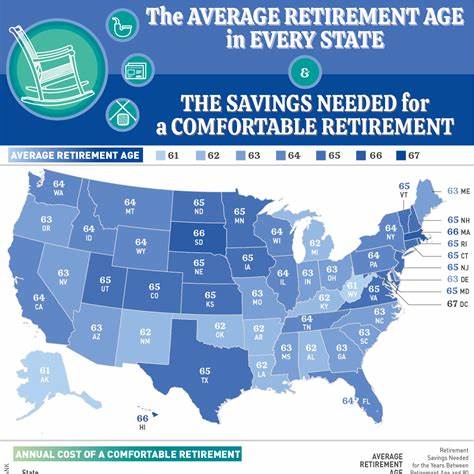
随着数字化时代的不断发展,PDF文档作为信息传递的重要载体无处不在,尤其在法律、金融、医疗和学术研究等多个领域具有不可替代的地位。然而,PDF格式虽然在内容呈现上极具优势,但其复杂的排版结构、缺乏统一的解析标准,使得从中提取结构化数据变得异常困难。正是在这样的背景下,OpenDataLoader-PDF应运而生,成为解决复杂PDF解析难题的创新开源工具。OpenDataLoader-PDF是一款专为结构化PDF文档解析设计的开源项目。它通过先进的规则引擎和智能算法,能够将复杂的PDF内容转换成适合后续自然语言处理和知识检索的Markdown和JSON格式。与传统解析工具不同,OpenDataLoader-PDF不仅重视文本提取,更强调文档的语义结构和空间布局,从而实现精准的多栏文本读取、表格结构还原和元素边界识别。
解析效率是衡量PDF处理工具优劣的重要指标。OpenDataLoader-PDF利用XY-Cut++算法,以极快的速度支持每秒处理百余页,无需依赖GPU设备,充分发挥CPU的计算能力,满足高负载文档处理需求。同时,该工具完全本地运行,不依赖云计算服务,保障了用户文档的隐私安全,尤其适合处理敏感信息。多栏文本解析一直是PDF读取的难点。一般解析器往往将多栏布局的内容简单依次读取,导致信息顺序混乱,影响后续理解。OpenDataLoader-PDF通过XY-Cut++算法有效区分页面中不同文本块,保证文本顺序符合自然阅读习惯。
此外,表格识别也是其亮点之一。该工具结合边框检测与聚类分析,精准重建表格的行列结构,包括合并单元格和复杂嵌套,确保数据信息完整传递。传统PDF解析时,页眉页脚等元素常常被误纳入正文,造成信息污染。OpenDataLoader-PDF内置智能过滤机制,自动剔除页眉、页脚、隐形水印及无效区域,保证输出内容干净利落,更适合用于构建检索系统或知识图谱。此外,为了支持多样化应用,OpenDataLoader-PDF提供多种输出格式。用户不仅可获得语义丰富、附带元素边界的JSON数据,还可生成结构化Markdown文本,方便整合进基于大规模语言模型的检索增强生成(RAG)管道,极大提升上下文相关性和回答准确率。
随着欧盟无障碍法规的推行,结构化和带标签的PDF变得尤为重要。OpenDataLoader-PDF能够充分利用PDF中的原生结构树,实现精确的语义提取,避免仅凭视觉版面猜测布局的技术瓶颈,为合规性文档处理提供强有力支持。此外,面对复杂表格及需要OCR识别的扫描件,OpenDataLoader-PDF还支持混合模式,结合本地规则处理与AI后端解析,在保证速度的同时,提高表格准确率,从而满足更为苛刻的解析需求。隐患安全问题也是现代文档解析不能忽视的方面。利用内置的AI安全过滤模块,OpenDataLoader-PDF自动检测和剔除潜在的隐形文本、页面外内容及可疑层,防范潜在的恶意提示注入,守护数据安全和业务稳定。作为一款面向开发者的开源项目,OpenDataLoader-PDF提供了跨语言支持,包括Python、Java、Node.js和Docker容器,便于集成进多种技术栈和企业级应用,同时官方还配备了完整的命令行工具和丰富示例,加速开发者的使用体验。
此外,它与知名的LangChain框架官方整合,极大简化了基于RAG的文档问答系统搭建过程,用户可以轻松加载PDF文档,快速构建智能检索和生成接口,赋能企业数字化转型。行业内的性能基准对比也证明了OpenDataLoader-PDF的优异表现,在保持高速处理的同时,兼具高准确率的阅读顺序判断和表格结构解析,明显超越许多竞品工具。未来,项目团队计划持续优化对多语言文档的支持,强化对增强现实和复杂文档格式的适配能力,推动更加智能化的文档理解应用。总的来说,OpenDataLoader-PDF以其本地高效、结构化精准和安全可靠的特点,为处理繁复的PDF文档提供了一个强大而灵活的开源方案,为开发者和企业构建智能文档处理与RAG管道奠定坚实基础。在数字信息爆炸的时代,选择一款可信赖的结构化PDF解析工具,能够显著提升数据的可用性和业务效率,OpenDataLoader-PDF无疑是你值得关注的重要助力。 。