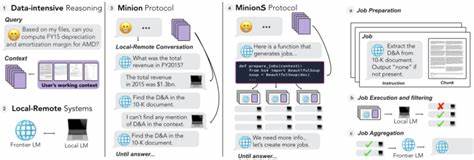
随着人工智能的迅速发展,大语言模型在自然语言处理领域展现出强大的能力。然而,这些模型通常体量庞大,运行成本高昂,尤其是在跨设备协作和长文本处理场景中,对硬件和计算资源提出了巨大的挑战。面对这些难题,MinionS协议应运而生,凭借其创新的本地-云端协作策略,推动了大语言模型的应用进入一个全新的阶段。 MinionS协议由斯坦福大学Hazy Research实验室研发,是一种基于分解-执行-聚合策略的协作机制,旨在优化小型本地模型和大型云端模型之间的协同效率。其核心思路是利用本地模型处理文档的分块和初步分析任务,而将复杂的任务分解和最终的综合推理交由云端模型负责,这种模式有效分摊了计算负载,极大地节约了云端调用成本。 具体而言,MinionS采用了远程模型先将复杂任务拆解成多个简单且并行的子任务,然后本地模型依据拆解结果分段处理各个文档块,最后云端模型对本地处理结果进行汇总和复核,确保输出的准确性与连贯性。
该机制突破了传统简单对话模型的限制,实现了更为高效且精准的文档处理流程。 其技术优势尤为显著。根据研究数据,部署一款8亿参数量级的本地模型,配合云端大模型协作, 可以实现近5.7倍的成本节约,同时仍然保持97.9%的云端模型性能。即便是参数更小的3亿模型,依然可以达到6倍的成本下降及约93.4%的性能恢复率。对比传统的仅通过云端模型处理,MinionS不仅节省了大量的运算资源,还大幅减少了令牌使用,从而降低了延迟和费用。 MinionS协议的落地应用场景丰富且多样。
对于需要深度文档分析的行业,如金融分析、医疗记录处理和科研文献摘取,MinionS能够极大提升处理效率,减少资金消耗,并确保数据隐私安全。对于需要处理长文本内容的任务,这一协议更能体现其优势,通过本地预处理有效降低云端负载,提升响应速度。此外,在用户关心隐私保护的时代背景下,MinionS保持重要数据本地处理的能力,使敏感信息无需频繁传输至云端,增强了数据安全性和合规性。 为了方便开发者和企业快速部署该技术,MinionS提供了完善的Docker容器化支持。用户可以在支持GPU的笔记本或工作站上通过简单配置,即可运行多种模型示例,并切换不同参数规模的模型以满足不同的精度和效率需求。例如,用户可以轻松将默认的llama3.2(3B参数)升级为qwen3(8B参数),以换取更高的准确率,定制体验更加灵活且符合业务需求。
通过MinionS的交互界面,用户能够直观比较传统远程模型独立处理和MinionS协作模式下的效率差异。系统展示了令牌消耗的明显下降,验证了协议设计带来的成本优势。同时,API密钥的安全管理和模型参数调整均极大方便了用户在不同环境和任务中的灵活应用。 从学术研究到开源项目的推广,MinionS协议已成为当前大规模语言模型领域中探索成本优化和性能平衡的典范。其实现方式不仅改变了传统云端独立推理的单一思路,还推动了边缘计算和云计算的深度融合,为未来人工智能系统设计提供了宝贵的参考。 总结而言,MinionS协议通过本地与远程模型的高效协作,带来了革命性的成本节约和性能接近云端的突破,有效满足了多样化的长文本处理和隐私保护需求。
随着其技术的不断完善与社区的活跃支持,预计在金融科技、生命科学、智能办公等领域将获得更加广泛的应用和认可。未来,借助MinionS协议的创新框架,大语言模型的普及和智能化进程必将迈上新的台阶,为行业用户创造更大价值。 。