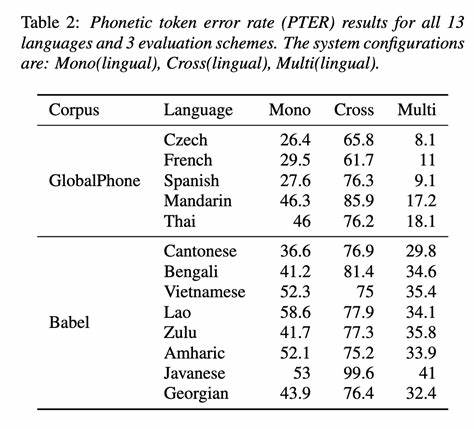
语音识别技术作为人工智能领域的重要组成部分,正逐渐渗透到我们日常生活的方方面面,包括智能助手、语音翻译、无障碍沟通等。传统观点普遍认为,多语种语音识别模型由于可以利用不同语言之间的共性,能够更高效地处理多种语言,因而在应用中更具优势。然而,最近的一项研究提出了不同的见解 - - 其揭示了单语语音识别模型在体积仅为多语种模型约1/30的情况下,依然取得了更优异的识别表现。这一发现不仅挑战了既有认知,也为边缘设备上的语音技术实现提供了新思路。 从技术层面而言,单语语音识别模型因其专注于单一语言的语音特征,可以更精准地捕捉该语言特有的音素、语调和口音变化。这种针对性优化使得模型能够减少复杂度,提升识别准确率,同时降低对计算资源的需求。
相比之下,多语种模型需要处理多种语言的差异,模型规模庞大且结构复杂,导致训练和推理的资源消耗较高,尤其在设备端部署时面临很大挑战。 边缘设备的兴起推动了轻量级语音识别模型的发展。智能手机、智能音箱、车载系统等对实时性和隐私保护的需求促使厂商优先考虑小巧且高效的模型。研究表明,经过针对单一语言进行精心设计与训练的单语模型,能够在保持极低参数量的基础上,显著降低错误率。如此一来,用户体验得到提升,同时设备功耗也得以控制,实现了性能与效率的理想平衡。 数据质量和训练策略也是单语模型表现优异的关键因素。
通过结合高质量的人类标注数据、伪标签数据以及合成语音数据,单语模型获得了丰富且多样的训练样本,这不仅弥补了部分语言资源匮乏的问题,也增强了模型的泛化能力。此外,微调技术的应用让模型能更好地适应特定方言和口音,进一步提高实际使用中的识别效果。 相比之下,多语种模型的优势在于其对多语言环境的适应能力,适合有多语种需求的全球化产品。然而,当设备资源有限或者特定语言使用成为重点时,庞大的多语种模型在效率和响应速度上存在明显劣势。尤其在实时语音交互中,延迟时间和准确率的平衡尤为重要,单语模型凭借其结构简洁和针对性强的特点,往往能够提供更稳定的用户体验。 更重要的是,单语语音识别模型在部分欠资源语言上的突破具有深远意义。
由于缺乏大量标注数据,这些语言传统上在多语种模型中表现不佳。然而,专门针对这些语言定制的小型单语模型,通过开发适配的数据采集与增强策略,成功提升了识别准确度,为语言保护和数字平权带来积极影响。 从未来发展趋势来看,单语和多语种模型并非简单的对立关系,而应形成互补生态系统。一方面,多语种模型可作为基础通用框架,为不同语言提供初步支持;另一方面,针对具体应用场景和语言特点的单语模型则可提供更优质的用户体验与响应速度。二者结合,可以实现灵活适配不同设备和需求的智能语音识别系统。 此外,随着神经网络压缩技术、知识蒸馏和高效训练算法等的不断突破,单语模型的尺寸将进一步缩小,性能持续提升,这为广泛部署在更多智能设备上奠定了坚实基础。
开发者和研究人员可以利用这些技术,设计出既轻量又高效的单语语音识别模型,满足日益多样的市场需求。 安全性和隐私保护同样是语音识别技术发展的重要考量。单语模型通过在本地设备上执行识别任务,减少了数据传输,降低了潜在的隐私泄露风险,符合当前用户对个人信息安全的高度关注。相比依赖云端的大型多语种模型,本地单语模型的应用更具优势,有助于在家庭、医疗和政府等安全敏感领域推广普及。 总体而言,最新的研究成果清晰展示了体积小巧的单语语音识别模型能够在性能上超越体积庞大的多语种模型,这一发现为语音识别领域带来了新思路和应用机遇。随着技术的不断演进,单语模型将在提升识别精度、降低延迟、节省计算资源及保障隐私方面发挥越来越重要的作用,推动语音技术向更广泛、更深入的方向发展。
未来,跨学科合作和产业界的紧密配合,将推动单语语音识别模型在智能硬件、语言服务、教育辅导等多领域的应用落地。技术创新与实践应用的结合,将最终实现语音识别技术的普惠化,为更多不同语言用户提供精准、高效、便捷的语音交互体验。 。