随着人工智能技术的快速发展,语言模型(LLM)在数据工程和AI构建领域的应用日益广泛。两种技术范式,检索增强生成(RAG)和模型上下文协议(MCP),成为行业讨论的焦点。虽然二者均能扩展语言模型的能力,但面向的挑战和解决方案截然不同。深入理解MCP与RAG的区别与合作方式,对于设计高效智能数据系统至关重要。检索增强生成(RAG)是一种通过外部检索机制增强语言模型知识的技术。其核心是先对文档、文章或对话记录等非结构化文本进行向量化处理,存储在向量数据库中。
用户提出问题后,将该问题转化为向量,检索最相关的内容片段,再将这些相关文本作为提示输入语言模型,从而生成基于领域知识的回答。RAG最大的优势在于能够处理大规模非结构化文本,特别适用于知识库、研究文献、客服文档或企业内部维基的语义搜索与内容召回。然而,RAG的局限也很明显。其数据新鲜度依赖于对文档的重新向量化,且难以处理数据库模式、实时系统状态等结构化信息。换言之,RAG更像是赋予语言模型记忆能力,专注于语义召回。相比之下,模型上下文协议(MCP)是一个用于将大型语言模型与外部工具和实时数据进行结构化连接的标准协议。
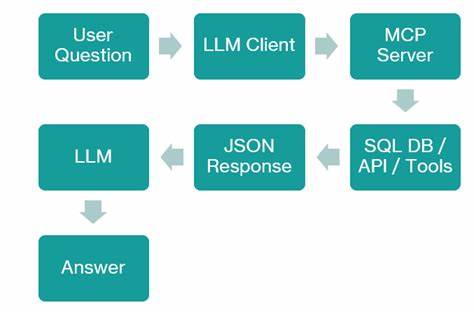
通过运行MCP服务器,开发者可以将数据库查询、数据表概况、API调用等功能以安全、清晰的形式暴露给MCP兼容的客户端。语言模型根据输入问题决定调用哪个工具,客户端通过JSON-RPC协议向MCP服务器发出请求,获得结构化响应后将其注入模型上下文,确保回答基于最新、精确的系统数据。MCP的核心优势是实时访问结构化数据系统,无论是雪花(Snowflake)、Databricks、PostgreSQL数据库,还是数据目录和对象存储,都能提供即时响应。同时,通过明确的功能暴露与调用权限管理,MCP避免了模型盲目猜测API调用的风险,保证系统的安全与可组合性。MCP不擅长语义搜索和长文本检索,更适合执行数据库查询、数据探查、质量检测等任务。RAG和MCP并非相互替代方案,而是高度互补。
可以将RAG视为"记忆",专注于非结构化文本的语义检索;而MCP则如"眼睛和双手",实现对结构化系统的主动感知与操作。举例来说,当客户提出关于账单问题时,RAG能够检索相关的故障排除文档,而MCP则通过SQL查询实时数据库,验证有多少用户当前缺少账单信息。将二者结合,能够构建从知识召回到实时执行的完整闭环流程,极大提升AI系统的智能水平和实用价值。对于数据工程师而言,MCP提供了暴露数据资源、检测数据缺失、追踪数据血缘、自动化数据质量检查的有效工具。MCP能够直接将诸如SQL查询、表结构分析、数据新鲜度检测等操作封装为模型可调用的函数,允许语言模型智能调度,无需通过手动导出和查询。结合外部丰富的扩展API,MCP还能实现自动填补数据空白,支持跨系统数据关联分析,这在构建复杂数据管道和监控中尤为重要。
语言模型与MCP的交互是通过基于功能声明的自动发现机制完成的。MCP服务器定义可用工具及其调用参数,MCP兼容客户端自动向语言模型告知这些信息。用户提问后,语言模型决定合适的工具调用,客户端将请求转发,服务器执行后返回结构化结果,客户端再将结果注入语言模型上下文,实现安全且高效的信息传递。这使得整个系统模块化、可扩展,且避免了模型无序猜测API调用细节的安全隐患。在实际部署中,MCP服务器可以通过简单的Node.js代码实现,安全限制例如只允许SELECT语句的查询,防止数据破坏。同时,针对表结构的统计分析、缺失值比例计算也可作为工具暴露给模型调用。
进一步,融合RAG的语义搜索功能,可以构建混合的MCP服务器既能访问结构化数据也能处理非结构化文档,满足更多应用场景需求。总结来说,RAG和MCP各自专注于不同类型的数据和应用场景。RAG以文档记忆为核心,适合信息检索和知识回溯;MCP则专注于实时数据访问与工具调用,适用于数据管道、质量检测和系统状态查询。合理结合两者,可以构建出既具备强大记忆力又能实时操作系统的智能AI助手,极大扩展语言模型在工程实践中的能力。未来,随着技术的成熟和生态的完善,MCP与RAG流水线的深度融合将在智能数据系统建设中发挥更大作用,成为数据工程师和AI开发者不可或缺的利器。 。









