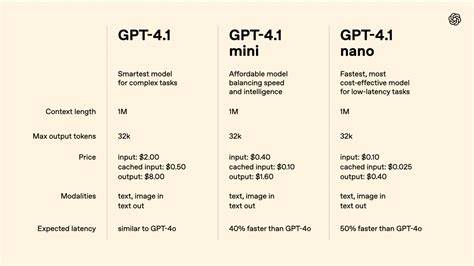
近年来,人工智能领域的进展日新月异,尤其是大型语言模型(LLM)的发展带来了前所未有的智能突破。作为这一趋势的重要探索,GPT系列模型不断刷新在语言理解和生成上的极限。近期,一项令人瞩目的实验利用GPT-4.1-mini模型,在经典游戏井字棋(Tic-Tac-Toe)中实现了击败更大规模模型GPT-4.1的壮举,背后的核心秘密是动态上下文和智能的少量示例学习。这一研究不仅展现了模型在游戏策略上的深度提升,也为如何借助上下文动态调整推动AI对复杂问题的理解提供了宝贵经验。 井字棋虽然看似简单,却具备极佳的测试智能系统能力。它的状态空间较小,反馈极快且游戏理论已被完全解决,使得任何完美策略均以平局告终。
然而,人工智能在此基础上如何优化决策路径、减少错误甚至利用对手弱点,成为观察模型“思考力”与策略灵活性的绝佳窗口。GPT-4.1-mini与GPT-4.1的对决即围绕这一点展开,充分利用了新一代AI工具Opper平台的强大功能。 Opper平台以其简洁高效的Python SDK和强大的内置特性,助力用户轻松搭建复杂的多玩家竞技环境。通过声明式定义、灵活的模型替换和数据追踪机制,研究者能够快速配置并运行大量LLM的比赛,提高实验的可控性和复现性。更重要的是,Opper支持自动的示例管理和上下文检索,这正是GPT-4.1-mini胜出的关键策略。 在这场井字棋锦标赛中,每个“选手”都是一个集成了OPPER函数和特定策略的独立模型实体,支持零示例、少量示例和链式推理不同形式的策略表达。
模型通过反复对弈积累胜利样本,借助余弦相似度对过去的成功数据进行动态检索和上下文补充,这种“少量示例在线学习”提升了模型的实战适应能力,也显著缩短了学习曲线。 动态上下文的妙用不仅仅体现在示例迭代上。当模型需要做出下一步决策时,系统围绕当前棋盘状态、玩家身份等关键信息构建丰富的上下文输入,保证模型在有限的信息窗口内最大化利用已有经验和策略逻辑。这样的设计,避免了简单硬编码的局限,也极大提升了模型的灵活度和推理深度。 比赛过程中,主办方使用Opper的异步调用功能,实现了高并发的比赛调度,极大提高了实验的执行效率。每场对局的详细过程和结果均被写入SQLite数据库,方便后续的深度分析。
借助内置的追踪与指标统计工具,研究团队能够实时监控每场比赛的移动次数、胜负比例及非法操作频率,从而对模型策略做出精细调整。 在结果分析中,GPT-4.1-mini以其动态上下文能力,在诸多排兵布阵环节展现出明显优势,频繁做出最优或接近最优的下棋决策,而较大GPT-4.1模型则因上下文静态、缺乏示例迭代而显得相对保守。这一胜利不仅验证了少量示例与链式推理结合的潜力,也揭示了大模型参数量并非衡量战术智慧的唯一标准。 此外,游戏结果中还体现了“先手优势”这一经典现象,X方取得显著更多胜利。通过统计分析,研究人员量化了这一偏差,为今后设计公平无差别的对局环境提供了理论依据。用户还可以根据实际需求调整比赛规则,如是否启用双回合制以均衡先后手影响,进一步丰富实验设计。
从开发者视角来看,Opper平台支持无缝切换模型,调整示例数量,只需修改少量配置代码即可实现多样化实验。其内置函数可视界面让模型调用一目了然,追踪界面则透明显示所有上下游调用,极大方便调试和性能调优。通过这些功能,研究者能够专注于策略创新而非繁琐的技术细节,真正实现“用最少的代码,做最高效的实验”。 未来展望方面,GPT-4.1-mini击败GPT-4.1的实验为利用动态上下文和在线示例学习开辟了重要路径。扩展此思路,不难预见更多领域的应用,如自然语言理解、对话系统甚至复杂决策支持,都能从中受益。此外,结合多模态信息、引入更细粒度的推理链条,也为AI理解和应对现实世界中的非结构化问题提供了可能。
总的来说,这场围绕井字棋的AI对决虽然看似简单,却蕴含丰富的技术和理论价值。借助Opper平台的自动化管理、精准追踪和高效执行,加之创新的动态上下文策略,GPT-4.1-mini证明了小巧模型在精心设计的策略支持下,完全能够挑战并超越体量更大的对手。这不仅提醒我们在AI设计中关注“智慧”的结构和环境条件,也敦促行业深入探索一切提升效率和能力的智能方案。未来,随着工具和技术的不断进步,相信更多类似的精彩挑战将不断推动人工智能技术的发展边疆。









