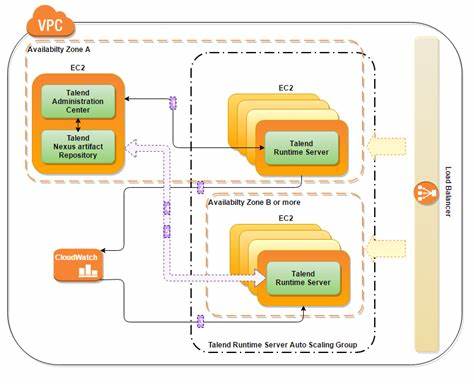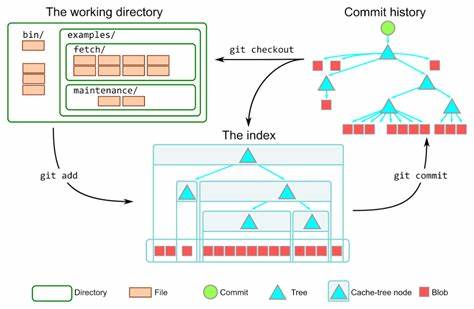
Git作为当今最流行的分布式版本控制系统,为开发者提供了强大且灵活的代码管理工具。在众多Git的功能中,索引(index)和缓存(cache)的概念往往让初学者感到困惑。通过理解索引与暂存区之间的关系,开发者能够更加精确地控制代码提交的内容,提高团队协作效率。本文将深入探讨Git中“缓存内容的更新”这一核心机制,剖析它的历史渊源、实际应用及其对现代开发流程的影响。回顾Git的诞生,不难发现Linus Torvalds设计Git时,灵感来源于其之前基于补丁和归档文件的工作方式。在早期,为了管理不同版本的内核源码,他采取了“打补丁”的模式,通过逐步应用补丁实现版本迭代。
然而,随着补丁数量激增,这种方式逐渐显得效率低下且难以维护。为此,Linus引入了目录缓存(directory cache),即将目录下的文件信息以一种紧凑且高效的结构存储起来。目录缓存相当于今天Git中的“树(tree)”对象的集合,能够快速反映目录结构变化并支持更灵活的版本控制。目录缓存的存储最初被保存在名为“.dircache”的控制目录下,其文件形式为“.dircache/index”,被程序内部变量命名为“cache”。这个缓存结构本质上是开发者对工作区快照的索引,实现了对源码文件的集中化管理。随着Git的发展,索引(index)这一词汇逐渐取代了“缓存”成为用户界面友好的表述。
索引更加直观地反映了该文件作为版本控制的“索引”,即对文件内容的引用与组织,使用户能够通过索引快速定位变更文件。虽然内部开发依旧沿用“缓存”这一命名,但在用户层面,“索引”成为概念核心。索引的作用是维护一个工作区当前状态的快照,记录文件路径及其对应的内容哈希。当修改代码后,开发者通过“git add”将变更加入索引,从而在准备提交时指定具体变更。这一过程通常被称作“暂存”,即将变更暂时存放在索引区域,等待后续提交操作。值得注意的是,Git中“缓存”一词如今主要作为形容词使用,描述“已缓存的内容”,即已经存入索引但尚未提交的文件状态。
虽然理论上“索引内容”应等同于“缓存内容”,但习惯用法中这一差异反映了用户与内部实现层的界限。命令行中的“--cached”选项常用来表示操作仅针对索引内容而非工作区,体现了索引作为一个独立层次的重要性。例如,使用“git diff --cached”可以对比索引与HEAD引用的提交内容,而非直接对比工作区文件的变动。“git apply”命令也支持“--cached”选项,意为仅修改索引内容,不触及工作区文件,这种方式极大便利了代码修补和回滚过程。相对应地,“--index”选项则促使命令同时操作索引和工作区文件,使变更保持同步。通过这些选项,Git赋予开发者灵活精细的控制手段,满足多样化的版本管理需求。
历史上,“git update-index”命令被用来精细管理索引内容,包括添加新文件和更新索引中文件的内容。虽然该命令依旧存在,但如今更多用户选择更简便的“git add”操作完成索引更新和文件添加,简化了日常操作。随着开发社区的发展,“暂存(staging)”这一表述逐渐盛行,用以描述将变更提交到索引这一行为。尽管“暂存”作为动词的出现增加了Git术语的多样性,但其语义与“add”高度重合。本质上,这两者都指向更新索引这一关键动作。暂存区即索引的另一个称谓,形象地描述了这是一个临时收集变更的区域,待提交时被一并写入版本库。
对于程序员和团队协作而言,掌握索引与暂存区的关系,理解缓存内容的更新方式,能有效避免不必要的错误和提交遗漏。通过灵活运用“git add”、“git rm --cached”等命令,可以准确控制哪些文件被纳入版本控制,哪些文件暂时保留在工作区未被追踪。进一步地,结合“git diff --cached”等命令,可以清晰洞察已暂存与未暂存的变更差异,提升代码评审和调试效率。Git的设计哲学注重速度和数据完整性,缓存与索引机制正是其核心体现。它们不仅实现了改动的精细管理,也为分布式环境下的版本同步打下坚实基础。开发者只需理解“缓存内容即索引中的快照”,即可高效利用Git强大的暂存能力,优化每日的开发流程。
总而言之,Git中的缓存与索引虽在历史和技术层面有细微差别,但对终端用户而言,理解暂存区的意义及其更新机制是掌握Git操作的关键。借助于合理的暂存操作,开发者能够灵活处理复杂项目中的多变代码,实现更精准的版本控制和协作管理。未来,随着Git功能的不断演进,缓存和索引的关系或许会变得更加明确和简化,但当前掌握它们的使用方式,依然是每一个现代开发者必备的技能。