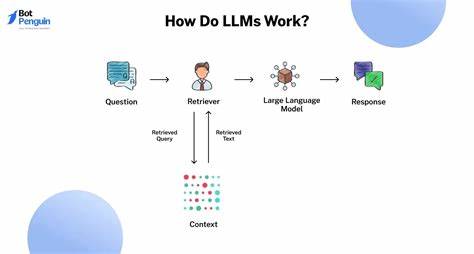
生命游戏(Game of Life)作为计算机科学和人工智能领域中的经典细胞自动机模型,一直以来都是算法性能优化的试金石。随着显卡计算能力的飞速发展,尤其是基于NVIDIA CUDA架构的并行化编程,生命游戏的实现迎来了全新的加速契机。然而,传统单步计算生命游戏在DRAM带宽瓶颈面前效率受到制约,不得不寻找更高效的存储和计算方案。本文将深入分析如何利用GPU的共享内存和寄存器等高速存储资源,通过多步融合计算方法显著提升生命游戏的执行性能。 经典的生命游戏规则简单,细胞基于邻居状态变化,通过迭代演化复杂图案。然而其并行计算的关键瓶颈在于数据读写频繁,尤其是每一步都需要访问大规模细胞矩阵的内存,这对于显卡的DRAM带宽提出极高要求。
以NVIDIA A40为例,DRAM到核心的传输带宽约为696 GB/s,但在每个细胞每步均需读写数据的情境中,这一数值很快成为性能瓶颈,导致单步运行时间大约为1.4毫秒。要突破这一瓶颈,必须重新审视内存结构和数据访问方式。 GPU的层次化内存设计是解决问题的关键所在。相比DRAM庞大但速度较慢,L1缓存位于每个流多处理器(SM)内部,容量虽小,但带宽极高,理论上可达67 TB/s。尽管完全利用这一高速缓存极为困难,但通过合理利用共享内存(实际上是由L1缓存支持的程序可控区域),可以大幅降低对DRAM的依赖,减少内存访问延迟。通过在每个线程块内部加载一定大小的细胞区域到共享内存,便能在局部范围内进行多步的生命游戏迭代计算,而不必每一步都访问DRAM。
具体实施过程中,线程块先从DRAM中载入一定尺寸的二维矩形细胞数据到共享内存。之后完成多达八步的生命游戏演化,而这些运算仅在共享内存内进行,无需读写DRAM。这种方式充分利用了共享内存的超高带宽,显著提升计算吞吐率。所有线程的同步通过__syncthreads()关键字保障,确保数据一致性和正确性。同时,为避免数据写入读取冲突,采用双缓冲的共享内存设计,交替进行状态更新。 然而,新方案在实现细节上也存在诸多挑战。
由于每一步计算依赖细胞邻居状态,边界区域的计算不完整,最终写回DRAM时需舍弃边界一定宽度的数据,导致线程块间必须部分重叠覆盖矩形区域,以确保整体计算正确完整。这种重叠设计稍微降低了GPU利用率,但相较于性能提升,这种代价是值得的。 从性能角度看,合并多步计算处理后,运行时间显著缩短至5.4毫秒,同时每步平均执行时间降至0.68毫秒,相比之前单步更新的1.4毫秒实现了近270%的性能提升。此时,DRAM带宽已不再是瓶颈,程序瓶颈转移到复杂指令的计算上,使得进一步增加并行步数收益有限。 为进一步优化,研究人员对核心计算循环进行了展开和重组。生命游戏需要统计$3\times3$邻域的细胞数量,传统方法是直接循环计算九个细胞的状态求和。
优化方案先计算$1\times3$行段的部分和,然后用这三个部分和快速合成完整$3\times3$邻域加和结果。这种策略减少重复计算,降低了指令数和内存访问,实现更高效率。 一次尝试中,开发者还引入了基于寄存器的小规模内循环。寄存器相比共享内存速度更快,但容量受限,而寄存器的过度占用会导致GPU调度能力下降,整体并行度降低,反而影响性能。实验结果显示,寄存器数组优化并未带来显著提升,反而因资源竞争稍微降低了利用率。 经过多轮测试与改进,最终方案在性能上取得了突破性进步,成为GPU并行计算中生命游戏加速的经典案例。
它不仅优化了共享内存和寄存器的利用,也明晰了多步计算策略在克服内存带宽瓶颈上的巨大潜力。 未来,随着GPU硬件架构的持续升级和编译器优化技术的发展,进一步提升多步融合计算的性能仍有空间。尤其是针对更大规模的细胞矩阵和更复杂细胞自动机模型,如何平衡共享内存使用、线程块划分与寄存器占用,以及优化核函数结构,将是研发重点。同时,异构计算结合如CPU-GPU协同处理也可能带来新的加速路线。 总结来看,通过合理利用CUDA中的共享内存多步融合处理,有效地绕过了DRAM瓶颈,实现了生命游戏迭代计算的极大提速。计算架构的层次化设计和数据访问模式优化为并行算法性能突破提供了重要思路。
对于从事高性能计算和并行算法开发的技术人员而言,该方案的设计理念和实现细节均具备重要价值,值得深入学习和借鉴。随着GPU技术的不断进步,加速版生命游戏无疑将成为实现更复杂生物模拟和自动机仿真的坚实基础。 。