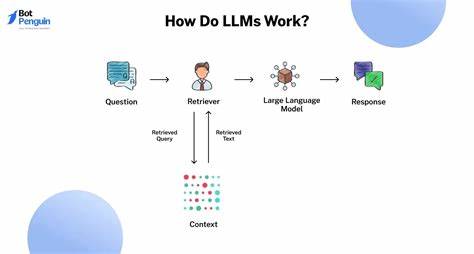
大型语言模型(Large Language Models,简称LLMs)近年来在人工智能领域掀起了巨大的浪潮,其强大的自然语言理解和生成能力为众多行业带来了巨大变革。无论是在内容创作、客户服务还是程序开发领域,LLMs均展现出卓越的应用潜力。本文旨在探讨如何高效利用大型语言模型,结合实际案例和用户经验,帮助读者深入理解其功能并优化工作方式。 许多专业人士将大型语言模型作为解决安全研究问题的助手,利用其快速检索和分析信息的能力替代传统的谷歌搜索。相比于单纯关键词匹配的搜索引擎,LLMs具备语义理解能力,能够根据具体问题生成针对性的解答和建议,从而显著提高安全审计和漏洞识别的效率。例如,研究人员可以通过与模型对话,探讨复杂的安全漏洞原理或代码安全风险,获得实用的解释和提示,节省大量的时间成本。
在程序开发领域,LLMs的影响尤为显著。许多开发者倾向于使用如Claude和ChatGPT这类语言模型进行编码辅助。通过模型的代码生成功能,开发者可以快速获得可执行且结构合理的代码片段,尤其在面临重复性较高、结构化需求明显的任务时表现突出。与此同时,部分工具如Cursor也支持以手动模式或智能代理模式生成和修改代码。虽然代理模式带来了高度自动化体验,但部分用户反馈更喜欢手动控制,以便根据具体需求对代码进行精准调整,确保代码安全和功能契合。 大型语言模型不仅在代码生成环节大放异彩,还逐渐渗透至产品设计和交互系统中。
越来越多的团队开始利用模型进行创意构思、产品文档编写以及用户支持自动化,提升整体工作效率。例如,市场营销团队借助LLMs快速撰写广告文案和说明书,而客服团队通过集成聊天机器人实现24小时不间断的客户沟通,及时响应用户问题和反馈。在金融、医疗等高度专业化行业,模型也被用于辅助数据分析、政策解读与医疗记录处理,将复杂信息转换为易于理解的语言,为决策提供科学依据。 尽管大型语言模型的优势明显,但在实际应用中也存在一定挑战。首先,模型的内容准确性有待进一步提升,尤其是涉及专业领域的细节,容易出现错漏或误导。其次,隐私与安全问题成为用户重点关注对象,敏感数据的保护与模型输出的合规性需要严谨把控。
同时,如何保证生成内容的原创性和防止潜在的偏见,也是需要持续关注和改进的方面。 为了更好地利用LLMs,技术社区和相关企业不断推出开放接口和集成方案,使开发者能够灵活调用语言模型实现各类需求。无论是内嵌于IDE的代码生成插件,还是面向终端用户的聊天机器人,均在提升使用便利性方面做出不少努力。用户可以根据自身需求和偏好,定制模型的运行模式、输出格式和交互逻辑,形成个性化的工作流程。 谷歌、OpenAI、Anthropic等领先机构为大型语言模型注入了丰富的数据和先进的训练技术,使得模型在理解自然语言、多模态融合以及跨领域应用方面不断取得突破。未来,随着技术成熟和算法优化,LLMs有望实现更高的交互智能和自主学习能力,成为无缝连接各类业务场景的核心驱动力。
总结来看,现阶段大型语言模型正处于快速发展和广泛落地的阶段,其应用范围从稳定实用的代码生成、安全分析工具延伸至跨行业的智能助手和创意创新平台。用户在选择与使用时,应结合自身实际需求,平衡自动化便利与人工控制的关系,同时关注数据安全和伦理规范,真正发挥出语言模型赋能工作的最大价值。 。