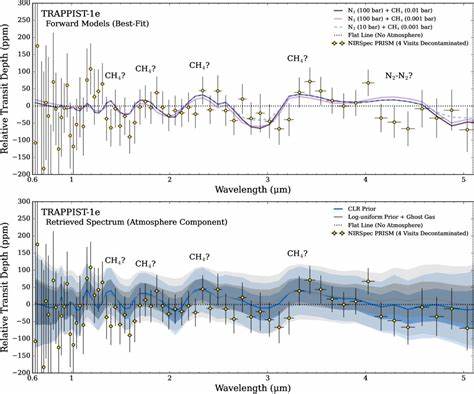
推荐系统作为互联网服务的核心引擎,承担着连接用户与海量内容的重任。随着用户行为数据量的爆发式增长,如何在保证推荐效果的同时降低计算成本成为行业亟需解决的难题。传统推荐模型高度依赖复杂的特征工程及手工调优,虽然能够实现一定的更新与维护,但难以灵活适应不断变化的用户行为。近年来,基于生成式模型的推荐方法因其端到端学习的优势备受关注,其中Meta提出的HSTU架构(即MetaGR)尤为抢眼,以纯Transformer架构直接从原始用户行为序列中学习,取得了卓越的排名效果。然而,模型计算复杂度高昂导致的部署难题也随之凸显。基于此背景,来自美团、人民大学和清华大学的研究团队提出了"双流生成式排序网络"(Dual-Flow Generative Ranking Network,简称DFGR),这不仅是对MetaGR的创新性改进,更是推荐系统领域效率与效果的双重革命。
MetaGR模型之所以计算资源开销大,核心原因在于对用户行为数据的输入序列设计。它将每次用户交互拆分为两个独立的Token - - 物品及其对应的动作,这样做虽然在捕获细粒度交互细节上卓有成效,但也使序列长度翻倍。考虑到Transformer模型中自注意力机制的复杂度与序列长度的平方成正比,输入长度的加倍意味着计算量呈现四倍增长。这对于拥有长交互历史的用户尤其致命,无法满足实时推荐场景的低延迟需求。针对上述瓶颈,DFGR提出了极具创新性的"双流架构"。其核心思想是将每次用户交互合并成单一Token,内涵物品与动作信息,从根本上将序列长度降回原始的N。
同时,模型构建两条并行流:一条"实流"负责携带真实动作信号,提供准确的历史上下文;另一条"假流"则用一个统一的占位符代替动作信息,负责预测真实动作。训练过程中,模型仅对假流的输出计算损失。乍看之下,假流似乎缺乏足够的动作信息支持,难以有效学习。然而,DFGR巧妙利用了两流之间的交互机制。在每个自注意力计算步骤中,假流的查询向量能够访问实流的键和值向量,从而间接获取丰富历史上下文,却不会直接"看到"要预测的动作标签,这极大地提高了学习效率和模型表达能力。该设计不仅实现了序列长度的最小化,也保证了信息流动和梯度传递的充分,使得模型在保持效果的同时大幅降低了计算负担。
经多项权威数据集和真实工业数据验证,DFGR表现卓越。公开数据集RecFlow与KuaiSAR上,DFGR相较MetaGR在AUC指标上提升约1.2%,并在实时推理速度上实现了4倍提升。更令人瞩目的是,工业级数据集TRec测试结果表明,DFGR不仅领先MetaGR,也超过了依赖数百个人工特征设计的行业主流深度学习推荐模型(DLRM)。这样的表现证明,端到端生成式方法若能解决效率瓶颈,确实有潜力成为推荐系统的未来主流。更为关键的是,DFGR遵循可扩展性定律,模型性能随计算资源呈现对数规律增长,这意味着投资于容量更大的模型将获得稳定且可预测的收益,为工业应用提供长远的发展动力。此外,双流架构的设计也启示了Transformer在序列处理效率上的新思路。
将序列拆分为内容与标签两条流,通过跨流注意力机制促进信息交互,既保留完整上下文,又避免了序列长度暴增的问题,这种范式有望被推广至其他序列建模任务中。DFGR代表了生成式推荐领域的一大进步。它以"行动即王道"为理念,将用户行为数据高效转换为精确预测的动作,实现准确且快速的排序决策。对于行业实践者而言,这意味着能够用更少的计算资源,快速迭代并部署先进的推荐模型,同时享受到超过传统手工模型的效果提升。总而言之,DFGR不仅破解了生成式推荐系统长期以来的计算瓶颈,更在实践中展示了端到端模型的无限潜力。未来,随着模型架构和训练策略的不断优化,生成式排序技术必将走入更多场景,成为支撑亿级用户个性化体验的核心利器。
随着推荐系统技术日益走向智能化与自动化,DFGR提供了宝贵的范例与方向,激励整个行业向更高效、更精准、更智能的目标奋进。 。