近年来,随着人工智能和深度学习领域的快速发展,计算性能的提升成为研究和应用的核心诉求。FP8(8位浮点数)作为一种极具潜力的低精度计算格式,因其能够在保证一定精度的同时大幅降低计算和存储成本,受到了广泛关注。尤其是在神经网络训练和推理中,FP8能够显著节省显存与计算资源,从而加速模型训练和推理流程。然而,在实际应用过程中,FP8的性能表现并非一成不变。近期,开发者们发现了一个颇为特别的现象:当FP8计算的内核(Kernel)名称中包含“cutlass”字样时,性能表现出现了显著提升,速度有时甚至比传统同类实现快100多万亿次浮点运算(TFLOPS)。这一发现引发了业界对GPU底层编译器和调度优化机制的关注,成为高性能计算中的一个热点话题。
首先,需要了解“cutlass”一词的背景。Cutlass是由NVIDIA官方推出的一个高效CUDA模板库,全称为CUDA Templates for Linear Algebra Subroutines and Solvers,致力于提供高度优化的矩阵乘法与深度学习计算模块。Cutlass通过深度优化的线程组织、内存访问模式和数据调度策略,实现了在不同GPU架构上的极致性能。虽然FP8是一种新兴的数据格式,但Cutlass的设计理念以及对现代GPU硬件的深度契合,使得“cutlass”这个关键词成为了相关内核的性能标志。 在某些基于Triton编程语言实现的FP8注意力机制内核中,研究人员发现,只要内核名称带有“cutlass”前缀,PTX汇编器(ptxas)会应用一套专门的指令调度优化。这种优化并非对所有内核名称均适用,而是通过字符串匹配的方式仅针对“cutlass”名称触发。
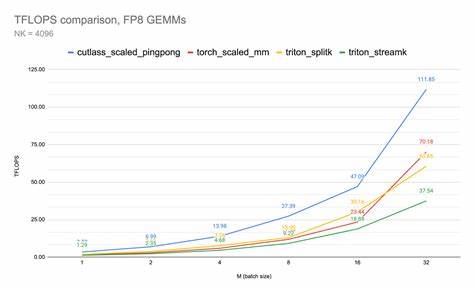
究其原因,ptxas在指令调度阶段插入了特定的硬件指令重排序策略,以充分利用NVIDIA GPU的Tensor Core硬件加速功能,使得FP8计算的吞吐量大幅提升。这种“硬编码”的字符串匹配机制尽管显得有些特殊,但却开辟了一条性能提升捷径。 该秘密的发现过程并不复杂,但却强调了软件名称对底层硬件调度潜在影响的重要性。开发团队通过对比内核名字含“cutlass”和不含“cutlass”的两组FP8内核性能,观察到TFLOPS的明显差距。例如在Z=4、H=32、D=64配置的注意力机制下,不含“cutlass”的FP8内核性能为约370 TFLOPS,而命名为“cutlass_”内核的性能数值则远远超过,达到470 TFLOPS甚至更高。这不仅仅是数字的差距,更是对运行效率与计算资源充分利用度的体现。
当然,这一优化并非简单地靠名称欺骗编译器就能长期使用。内核命名影响调度优化机制,其根源在于厂商对特定库和代码路径的高度优化。过度依赖字符串匹配可能带来兼容性风险,比如在不同驱动版本或者硬件平台上可能出现未定义行为。同时,这类优化很可能是实验性、非公开的,盲目应用可能引发精度问题或执行错误。由此引发的安全与稳定性议题也成为开发团队的重要考量。 FP8的应用本身就伴随着精度和稳定性的挑战。
作为一种极低比特宽度的浮点格式,FP8减少了尾数位数,导致计算过程中潜在的舍入误差增多,不过其在深度学习加速中的潜力不容忽视。利用“cutlass”命名节省的巨量时间和计算资源,有利于加速超大规模模型训练和推理作业,尤其适合于上下文窗口极大的Transformer模型。但前提是确保精度保持在容忍范围之内,否则性能优势难以转换成实际价值。 业界对此现象的兴奋不止于性能提升本身,更在于它暴露了底层编译链中的优化魔法。PTX汇编器作为连接CUDA代码与GPU硬件指令的桥梁,执行着复杂的指令生成与调度,内核名称竟然成为调度决定因素,极大地体现了软件定义硬件特性的深刻变革。如何在保证开放性和可预测性的同时,借助这些隐秘优化,成为GPU加速框架用户和开发者的共同课题。
针对这一现象,不少专家建议探索更正规化的优化接口。相比硬编码字符串匹配方式,期望NVIDIA及相关厂商能够引入官方支持的PTX指令或者编译选项,能够在无需改名的情况下开启相同的性能加速。这样做不仅能提升代码的可维护性和复现性,还能避免潜在的不兼容风险。在未来的编译器版本和GPU架构中,这或许成为推动FP8以及更低精度计算普及的关键所在。 从实际应用视角看,FP8性能的提升对深度学习训练和推理场景意义重大。在模型参数巨大、算力需求攀升的趋势下,性能提升意味着更低的训练成本、更快的调试迭代及更广泛的部署可能。
特别是在自然语言处理、大规模图像识别等领域,长上下文和大模型规模对计算带来的挑战急需通过软硬件协同优化手段予以缓解。 此外,这一发现也为开源社区和深度学习框架维护者提供了优化新思路。如何合理设计内核名称、灵活控制编译流程,甚至在框架层面引入策略以更好地利用底层硬件特性,成为科研与工业界关注的热点。诸如Triton等新兴编程模型,通过高层抽象控制内核编译,具备激活类似“cutlass”优化点的潜力,未来或引导一波以编译器驱动性能突破的新潮流。 尽管现阶段FP8性能提升的秘诀藏于“cutlass”字样,但它揭示的本质是软硬件协同设计的力量。未来,随着GPU架构日益复杂与智能化,底层优化必然更加依赖编译器深入理解硬件并智能调度。
如何平衡性能、稳定性和易用性,将决定FP8等低精度计算能否真正成为加速基础设施的中坚力量。 总结来看,FP8计算因内核名称含有“cutlass”而获得速度飞跃,体现了GPU指令调度背后的巧妙优化机制。这种现象令GPU编程者们意识到,代码命名和编译配置并非表面细节,而是影响性能的关键因素。对FP8的谨慎采用与未来官方优化接口的期待并存,将推动行业迈向更高效、更智能的计算新时代。对于追求卓越性能的科研人员和开发者,深入理解和利用这一规律,将为项目带来显著竞争优势。









