随着人工智能技术的飞速发展,大型语言模型(LLM)已成为许多企业数据处理和智能决策的核心。然而,众多企业在将LLM应用于复杂且多样化的业务数据时,常常面临准确率低、信息断层和误导性回答的问题。这些困难的背后,反映出传统数据库结构与人工智能认知模式之间存在的巨大鸿沟。近年来,RDF(资源描述框架)作为构建知识层的基础技术,正在被越来越多的专家和企业认可,并成为人工智能系统提升智能水平的自然选择。首先,理解LLM与传统数据库之间的摩擦有助于揭示RDF的独特价值。LLM依赖于对语言模式的识别和推理能力,但传统SQL数据库设计重点在于存储效率和数据管理,数据与元数据被分散存储,而且表与表之间的关系往往通过复杂、难以直观理解的外键等机制隐含表示。
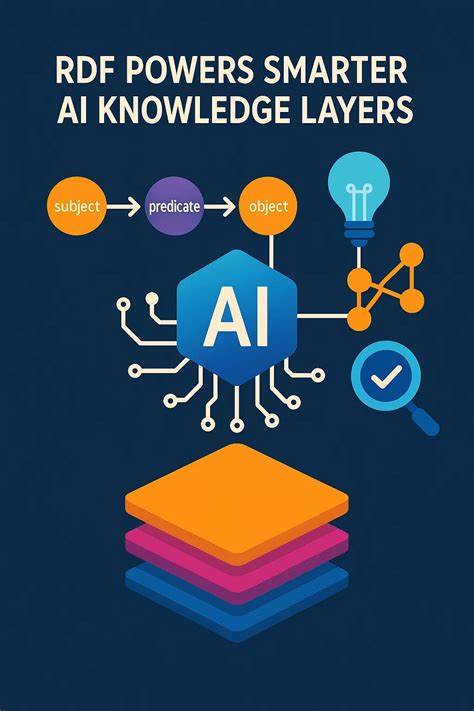
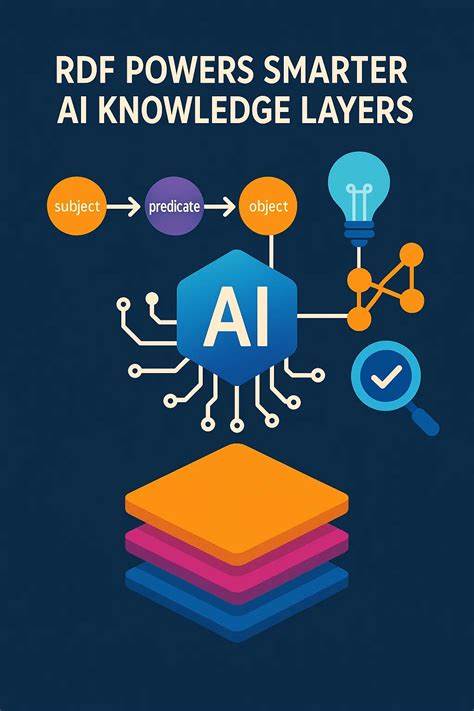
这样的设计造成LLM在处理数据关系时需要大量猜测和模式匹配,容易出现理解偏差,从而引发解答错误甚至"幻觉"。反观知识图谱则采用以实体和关系为核心的图结构,将现实世界的知识模型以更加语义化、直观的形式展现出来。知识图谱中每一条信息都以三元组形式保存,类似人类语言中的主谓宾结构,使得机器能够更好地捕捉事实之间的联系。在实践中,研究显示引入知识图谱能够使LLM在企业数据处理上的准确度提升三倍以上。这一显著的性能飞跃不仅归功于图结构所蕴含的语义清晰度,更因为知识图谱通过RDF标准解决了知识层中最核心的挑战 - - 身份识别问题。知识图谱必须解决"这两个实体是同一事物吗?"这一问题,尤其在企业跨系统、跨部门整合数据时尤为关键。
传统的标识符往往局限于单一系统内部,存在重名、歧义等难题,导致数据孤岛和信息不一致。RDF通过使用国际资源标识符(IRI),借助于互联网地址的体系结构,为任何实体赋予全球唯一且可解析的身份。这种身份机制不仅避免了重复和冲突,还自然支持数据的联邦查询与跨域整合。IRI支持层级结构和多语言编码特性,更适应全球化、多元化的业务需求。IRI的设计理念源自互联网技术的成功经验,它赋予了数据资产以网络链接的属性,允许系统在查询时不仅确认实体身份,还能追溯其语义来源和上下文,实现对知识的动态拓展与精准检索。这种明确的身份定义使得LLM面对复杂关系时无需猜测,能够基于清晰的图谱路径进行推理,大幅降低推断错误和数据混淆。
许多企业在未采用RDF的情况下,会自行研发一套基于映射表的统一标识体系,短期内似乎满足需求,但随着系统规模和复杂度增长,维护成本急剧攀升,性能瓶颈显现,项目进度与预算不断超标。对比之下,采用RDF及其丰富的生态系统,可以借助成熟的工具和标准,快速构建规范化、可扩展的知识层,避免重复造轮子,节省大量投入。历史案例清晰展示了这种选择的重要性,比如BBC拥有基于RDF的语义网平台,实现海量内容的自动生成和多渠道分发,显著降低人力成本和运营难度。Uber和Neo4j两大技术巨头在知识图谱建设上的转变也证明了RDF协议的不可替代性。RDF的三元组模型本质上与人类认知和自然语言表达形式高度契合,使其成为LLM优化的理想基础。三元组中的主语、谓语和宾语不仅表达了事实,更携带了丰富的语境信息,是实现智能推理和知识共享的原子单元。
通过RDF构建的知识图谱能够实现多维度的关联查询和语义过滤,帮助企业从海量数据中提炼价值,支撑更加精准的业务决策。此外,RDF的开放标准性质促进了跨系统、跨行业的数据互操作性,推动知识生态圈的建立。推动RDF普及还有助于解决AI系统的可解释性难题。由于所有数据元素及其来源在知识图谱中都有完整的标识和出处,LLM能够清晰地展现其答案背后的依据和权威,这对于合规性要求高的行业尤为重要。随着数据量和模型复杂度的提升,人工智能系统对于知识层的依赖只会越来越深。构建稳定、标准化且可扩展的知识层,将直接影响人工智能技术能否转化为切实的商业价值。
RDF提供了历史验证的架构基础和最佳实践指引,帮助企业避免陷入重复建设的陷阱,快速构建信息互通和语义统一的智能平台。未来,随着AI与物联网、大数据等技术的进一步融合,RDF的作用将更加突出。其在身份一致性、数据联邦和语义丰富度方面的优势,将助力实现真正的智能互联,推动智能应用走向深度落地。总而言之,RDF并非单纯技术选项,而是知识表示的一种必然进化方向。它利用互联网的广泛影响力与技术优势,解决了知识层构建中的根本性矛盾,使AI系统的数据理解更加准确、连贯和透明。对于寻求利用人工智能驱动业务创新的企业来说,拥抱RDF构建知识层,既是提升智能水平的关键一步,也是在变化迅速的数字时代立于不败之地的战略抉择。
选择RDF,即是搭建起一座连接现实世界知识与人工智能推理能力的桥梁,为智能系统注入持久生命力和发展潜力。 。