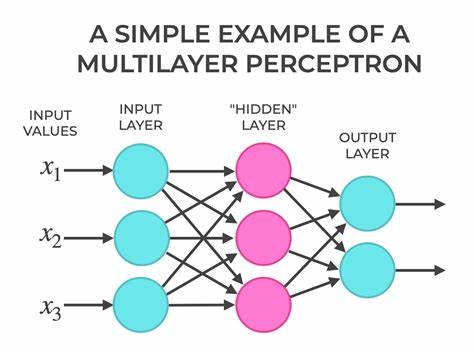
感知机是人工神经网络发展的关键节点,它不仅继承和发展了早期的MCP神经元模型,还开创了机器学习算法的新纪元。1957年,心理学家弗兰克·罗森布拉特(Frank Rosenblatt)在MCP神经元模型的基础上提出了感知机模型,这一创新使得机器能够通过学习自动调整权重,从而实现对数据的分类,这在当时无疑是一大突破。感知机的诞生为后来的深度学习和复杂神经网络的发展奠定了坚实的基础,也让人们第一次看到了机器通过训练自我改进的可能性。传统的MCP神经元模型依赖于预设的权重和阈值来实现基本的逻辑门功能,如AND、OR和NOT。然而,由于只能使用整数权重且需手动编程,MCP神经元在处理复杂任务时显得力不从心。感知机则通过引入一种简单的监督学习算法,使得权重可以根据训练数据自动调整,极大地增强了模型的灵活性和适用范围。
感知机作为二分类器,主要用于将数据分为两类:正类和负类。在训练阶段,模型通过不断比较预测结果与真实标签,调整权重向量,逐步优化决策边界,使得分类错误的样本逐渐减少。其核心机制是通过计算输入向量与权重向量的加权和,判断结果是否超过阈值,并据此输出预测类别。感知机的学习算法本质上是一种线性分类器,通过调整权重向量的位置和大小,寻找可分离数据的最佳线性决策边界。算法初始化时,权重通常被设为零或很小的随机数。随后对每个训练样本进行预测,如果预测错误,权重便会根据误差乘以学习率和输入向量的值进行调整。
这种方法保证了模型逐步收敛于一个能够较好分类的权重配置。学习率作为感知机训练中的重要参数,决定了权重更新的步伐大小。较小的学习率会使得模型收敛速度较慢,但更稳定;而较大的学习率则可能导致训练过程呈现震荡,甚至无法收敛。选择合适的学习率对于保持训练效率和模型准确度具有重要意义。例如,当学习率设置过小时,权重更新会非常有限,训练过程变得缓慢,模型可能无法在有限的时间内找到合适的分割平面。相反,过大的学习率则可能引入过度调整的问题,使模型错过最佳解。
尽管感知机在其诞生时期带来了革命性的进展,但它也存在不可忽视的缺陷。最为显著的是,感知机只能处理线性可分的数据问题。换句话说,如果数据的分类边界呈现非线性特征,感知机算法将无法给出正确的分类结果。这一局限性在1969年由计算机科学家马文·明斯基(Marvin Minsky)和西摩·帕普特(Seymour Papert)在他们的著作《感知机》中被深刻指出,引发了后来长达十余年的人工智能冷却期,也就是所谓的"人工智能寒冬"。这段期间,许多研究机构减少了对神经网络和感知机研究的投入,转而关注其他方向。但感知机的意义远不止于此。
它开创了基于数据驱动的自适应学习机制,为后来多层神经网络和反向传播算法的提出奠定基础。早期的"叛逆"科学家们在学界承受质疑的同时,坚持推动人工神经网络的发展,最终迎来了现代深度学习时代的爆发。在感知机模型中,权重调整的核心公式体现了监督学习的本质:通过比较模型预测和真实标签的差异,动态更新参数。这与现代机器学习中误差反向传播的思想有内在联系。具体而言,当感知机预测错误时,权重向量会被增加或减少相应的值,以修正对这一训练样本的分类。这种简单的局部规则,使得整个模型能够逐渐优化决策边界,提升整体的分类性能。
与此同时,感知机的设计也非常贴近生物神经系统的运行机制。它模拟了生物神经元通过加权信号总和决定是否激活的过程,将生物学中的神经元启发转化为数学模型。输入信号的加权累积、阈值激活以及输出信号的产生,形成了一个简洁而强大的信息处理单元。随着计算力的提升和理论的深入,感知机的概念被不断延展。通过引入非线性激活函数、多层结构和复杂优化策略,人工神经网络逐渐克服了线性局限,实现了对图像识别、自然语言处理和语音识别等复杂任务的突破。今天,虽然感知机作为单层线性分类器已逐渐被更先进的模型取代,但它不可忽视的历史地位和理论价值仍然被广泛认可。
研究感知机不仅有助于理解现代深度学习的算法基础,还能启发我们在设计新型机器学习模型时,如何巧妙结合理论和实践。总结而言,感知机是人工智能发展史上的一个重要里程碑。它从单纯的逻辑门模仿进化为具有自学习能力的分类器,首次将监督学习算法的思想引入神经网络领域。虽然存在显著的局限性,但感知机的诞生及其背后的学习思想激发了后续几十年人工智能技术的飞速发展。对于今天的研究者和技术爱好者来说,深入了解感知机的原理及其历史背景,是理解人工智能领域演进脉络和未来趋势的关键一步。 。