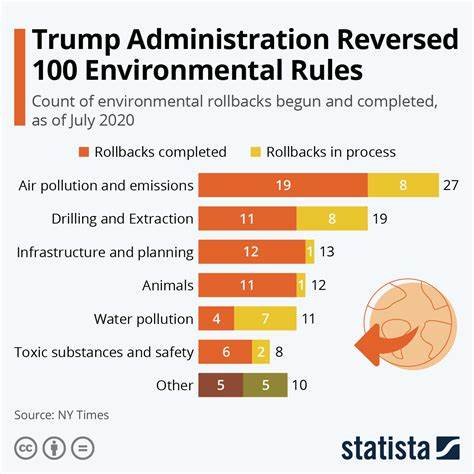
在现代数据驱动的时代,网络数据的快速下载与处理成为许多开发者和数据科学家面临的重要挑战。尤其当面对大量的URL链接需要批量下载时,如何有效利用计算机资源和网络带宽成为提升整体效率的关键。Python作为一种灵活且功能强大的编程语言,提供了各种并发与并行处理的方案,其中concurrent futures模块因其简单易用和功能强大而备受欢迎。通过合理运用concurrent futures,开发者能够充分调度多核CPU资源,实现并发下载,最大化地饱和带宽,从而显著提升数据下载速度。本文将深入介绍利用Python的concurrent futures模块进行多线程下载的核心技巧,结合requests库和重试机制,详解整个流程并分享实际代码示例,帮助读者掌握高效下载的关键手段。首先,带宽资源的完全利用是提升网络数据抓取效率的基础。
传统的串行下载方式受限于网络延迟和单线程吞吐量,往往无法充分发挥现代宽带网络优势。在多核处理器普遍配置的今天,利用多线程并发执行任务成为突破瓶颈的有效方式。Python的concurrent futures模块通过ThreadPoolExecutor为多线程任务管理提供了统一接口,简化了线程池的创建与调度,使得多线程编程更加直观和安全。应用concurrent futures时,推荐结合requests库,以其强大的HTTP请求功能精准控制下载过程。为了确保下载的稳定性与鲁棒性,采用HTTPAdapter配合Retry机制,有效处理网络抖动、断线重连等异常情况,提高任务的成功率。实际使用中,构造包含待下载URL的pandas DataFrame是管理大量链接的理想形式,方便数据操作和批量处理。
通过ThreadPoolExecutor创建的线程池,通常建议线程数设定为CPU核数的两倍或更高,可以兼顾计算和IO等待时间,充分利用带宽与计算资源。在下载函数中,利用requests的流式下载特性,分块读取文件内容并写入本地,避免内存占用过高,同时提升大文件处理效率。与此同时,为了防止因瞬时请求过多导致服务器拒绝响应,合理设置重试次数和退避时间,是保证任务连续稳定执行的关键。综合这些实用技巧,构建起一个稳定、高效且易于扩展的并发下载框架,实现对带宽资源的最大化饱和,不仅显著缩短批量下载时间,也为后续的数据分析和处理打下坚实基础。除了直接的下载速度提升,采用concurrent futures的并发方案还带来灵活的任务管理优势。开发者可以轻松实现任务提交、状态查询和异常捕获,配合日志记录,实现全流程的监控和优化,保障项目的可维护性和透明度。
未来,随着网络环境和硬件配置不断提升,利用Python进行智能化带宽管理与动态线程调度的探索将成为趋势。通过结合异步编程、负载均衡与带宽感知算法,可以进一步突破性能瓶颈,推动下载任务向智能化、高效化迈进。总而言之,借助Python concurrent futures模块的强大能力,配合requests库和合理的重试策略,能够实现并发下载的高效执行,满足大规模网络数据抓取的需求。掌握这些技术,不仅能够提升任务完成速度,也为开发者提供了提升系统性能和用户体验的新路径,是数据处理领域不可或缺的重要工具。随着网络应用场景的多样化和数据量的激增,掌握高效、稳定的并发下载技术显得尤为重要。不断优化代码结构、提升错误恢复能力、合理调节线程数,都是实现带宽饱和和高效利用的关键环节。
期待更多开发者借助Python生态系统的丰富资源,打造出更加智能且高效的数据下载解决方案,推动行业整体技术水平的提升。 。