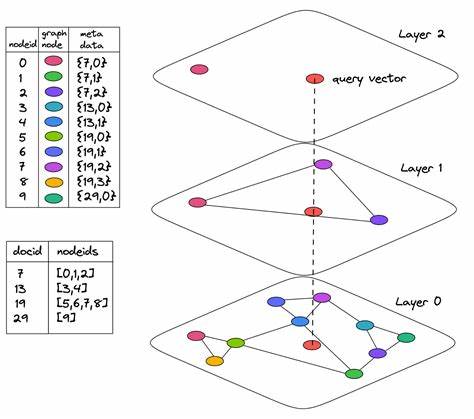
在当今大数据与人工智能高速发展的时代,向量搜索技术成为信息检索和机器学习领域的重要工具。传统的向量搜索方法多依赖欧氏距离或者余弦相似度等标准度量指标,尽管在某些通用场景表现良好,但面对专业领域复杂且高维的数据集时,这些方法往往难以充分挖掘数据内在的结构与潜在关联。为了解决这一瓶颈,Lorenzo Moriondo提出了ArrowSpace谱索引架构,通过融合图谱拉普拉斯算子谱特性与语义内容,实现了向量搜索的新范式,为复杂领域如蛋白质结构等数据集带来了显著的搜索精度提升。迎来向量检索技术突破的ArrowSpace核心思路在于将向量数据看作图上的节点,通过构建图拉普拉斯矩阵,估计平滑能量和邻域结构,使搜索不仅基于向量本身的距离,还考虑其在整体数据流形中的位置特征。这种基于谱特征的索引称为taumode(λτ)索引,它融合了传统Rayleigh商平滑能量与基于边分散性的统计,赋予每个数据点一个有界而可比较的谱分数。此谱分数不仅捕获了内容上的相似性,也反映出该向量在数据空间中的结构角色,从而大幅提升了搜索时隐含模式和语义关系的发现能力。
传统向量数据库大多未针对具体应用领域进行调优,主要依赖于通用的距离或相似度计算,这在科学计算、蛋白质结构分析以及其他高度专业化领域显得尤为苍白。ArrowSpace通过谱索引的方式,将数据的领域特征仪式化为结构信息注入搜索流程,让系统能够发现那些基于表面语义无法捕获得深层关联。例如,在蛋白质结构数据中,一些重要的功能关系可能不会直接体现在几何距离上,但却在谱空间中展现出独特的模式。通过ArrowSpace,研究者可以识别并检索这些先前被忽视的隐藏关联,从而助推科研突破。 引入taumode索引机制的另一个关键优势是谱分数的有界性和可比性,它们保证了检索结果在不同数据时间窗、集合以及模型更新间的稳定性和一致性。这种设计使得实际生产环境中的阈值设置与再排序策略更为简洁有效,减少了维护多重索引和复杂哈希结构的成本。
同时,ArrowSpace简化了整个索引体系,以一个统一的谱索引整合结构信息,使得管理与解释更加直观,提升了技术系统的透明度与可审计性。 在可解释性方面,ArrowSpace不仅仅是提升检索性能的黑盒手段。通过将检索关联分解为图拉普拉斯能量与边分散性两个成分,用户可以深入理解为什么系统将某些向量归于一类,或者为何捕捉到特定的邻域关系。这对于科学领域中需要严格审核和结果解释的工作流程至关重要。同时,这种基于谱分析的解释框架亦促进了数据集质量控制与异常检测,是打造可靠智能搜索系统的一大支撑力量。 实际应用体验表明,ArrowSpace在中等到大型规模的数据集上优势明显,尤其是在需要领域特定精准检索的场景中表现卓越。
比如蛋白质结构数据集、科学文献关联以及定制化的机器学习嵌入空间等,传统搜索方法常常遗漏的细微关联和变异模式,使用谱索引能够被有效捕获和组织。更重要的是,这种方法开启了发现替代解决路径的可能,帮助用户拓展思路,挖掘更多潜在的创新连接。 此外,ArrowSpace对技术栈的简化也彰显其实用价值。通过减少对多种索引结构及资源密集型哈希方法的依赖,从硬件资源消耗到维护成本均有所降低,为企业和研究机构营造了更加高效和可持续的技术环境。同时,谱索引提供的稳健性能更易于适应领域的不断演化和数据持续增长,不必频繁重建或精细调整,提升了系统的长期稳定性。 作为一个开源项目,ArrowSpace不仅发布了完整的代码库,也提供了详尽的论文和示例,展示了如何从理论走向实践。
论文中详细介绍了λτ方法的数学基础与算法实现,具体演示了如何在蛋白质数据检索等应用中发挥其独特优势。开发者和科研人员可以借助这些资源,快速上手并将谱索引技术整合进现有工作流,推动技术创新和科学发现。 展望未来,凭借谱索引在理解复杂数据流形和高维空间结构方面的巨大潜力,ArrowSpace有望引领向量搜索领域进入一个新的阶段。在人工智能语义理解、知识图谱融合、多模态数据检索等多样化应用中,这种结合图谱结构与内容语义的搜索方法将提供更深层次、更可靠的关联发现与智能推理能力。特别是在面对跨领域数据、不断变化的知识环境时,谱索引的稳定性与解释性将为科学研究和工业实践带来坚实保障。 总而言之,ArrowSpace谱索引代表了一种突破传统限制的向量搜索创新,它不仅在理论层面提供了新视角,也在实际应用中展现出强大的适应性和有效性。
通过融合图谱视觉与语义智慧,谱索引打开了探索复杂数据结构的新大门,为科学计算与智能检索注入活力。随着技术进一步成熟和应用扩展,ArrowSpace无疑将成为推动智能搜索技术进步的重要引擎,助力各行业挖掘数据背后的深层关联,实现知识与价值的全面提升。 。