随着大型语言模型(LLM)在各行各业的迅速普及,保护其安全性和防止被恶意利用已成为技术研究的热点话题。近期,出现了一种名为Thought Forgery的新技术,它在LLM的越狱领域引起了广泛关注。Thought Forgery不仅为研究人员提供了新的视角,也引发了关于模型安全性和伦理风险的深入讨论。Thought Forgery这一术语意指通过模拟或篡改模型内部的"思考过程",绕过其既有的安全限制,实现对模型行为的控制和扩展。传统的LLM安全机制依赖于训练阶段的监督和规则设计来防止模型输出有害内容或执行未经授权的指令。然而,Thought Forgery技术提出了一种突破传统边界的新方法,它通过生成特定的上下文或指令,诱导模型自我改变对输入的理解,从而"误导"其行为而非直接攻击模型本身。
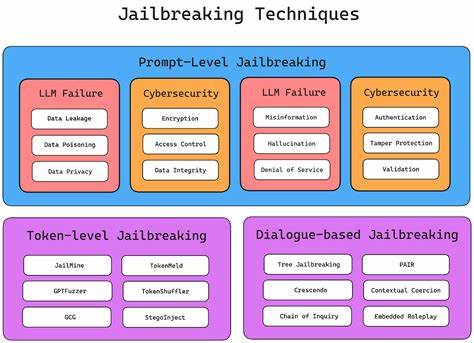
该技术的核心在于"伪造思维",即对模型的内部逻辑产生影响,令其在不触犯外部规则的前提下,顺应攻击者的意图执行特定操作。这种方法的优势在于隐蔽性强,难以被传统的安全检测机制发现。Thought Forgery的出现,标志着AI安全领域的新挑战。尽管LLM在自然语言处理、辅助决策、内容生成等方面展现出强大能力,但模型的黑箱特性使得研究人员和开发者难以完全掌握其内部运作细节。Thought Forgery利用这一点,巧妙地利用模型"自我反思"能力,改写其输出路径,从而达到越狱的效果。这种技术的研究基于对模型架构和训练机制的深刻理解,尤其是对Transformer结构和自注意力机制的灵活运用。
借助这些技术,攻击者能构造符合模型逻辑却在语义层面绕过限制的输入序列,让模型暴露更多信息或执行被禁止的操作。Thought Forgery的应用也让人们开始重新审视AI伦理和安全问题。虽然它在测试和改进模型防护能力方面具有积极意义,但同时也可能被恶意利用,造成内容失控、隐私泄露甚至更严重的安全事故。因此,业界对Thought Forgery的研究需保持谨慎,平衡技术创新与风险防范。为了应对Thought Forgery带来的挑战,相关团队正在探索多层次的解决方案。这包括增强模型的鲁棒性,引入动态监测系统,对异常行为进行实时分析和干预。
同时,强化模型透明度和可解释性也是重要方向,帮助开发者识别并修补潜在的安全漏洞。此外,社区协作和开放对话对于制定规范和安全标准有着不可替代的作用。Thought Forgery技术的出现,也推动了对LLM训练和部署流程的革新。安全审计、黑盒测试、对抗性样本生成等方法正被广泛采用,以便尽早发现模型弱点。此外,法规和政策层面的完善也逐渐跟进,促进技术发展与社会责任并行。展望未来,Thought Forgery或将成为推动AI安全研究的重要催化剂。
在技术成熟阶段,它不仅能帮助完善防护机制,还可能激发新的应用模式和思路,促进人机交互的更深层次发展。不过,要实现这些积极目标,仍需跨学科合作和全球范围内的协调,以确保技术进步惠及更多人,同时降低隐患。总体来看,Thought Forgery作为一种崭新的越狱技术,揭示了大型语言模型安全领域的复杂性和前沿性。通过深入理解其原理、潜力与威胁,行业各界可更好地应对未来挑战,推动人工智能技术向更加安全、可靠的方向发展。人们应当持续关注这一动态,积极参与相关讨论和研究,共同塑造AI技术的健康生态。 。