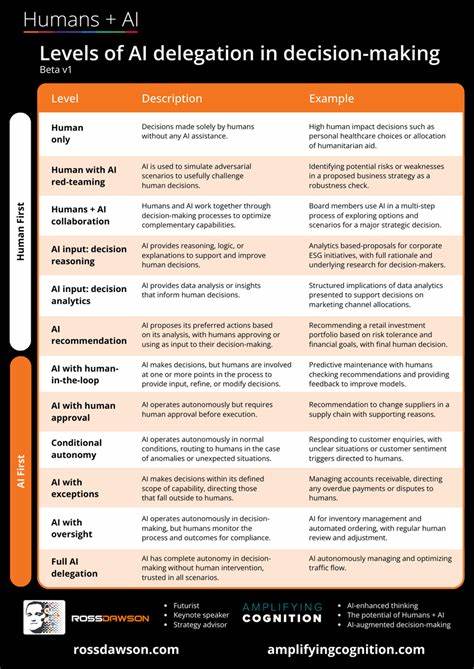
人工智能,特别是大型语言模型(LLM),正以前所未有的速度在软件开发领域掀起变革。AI辅助编程工具因其迅速生成代码的能力,极大地提升了开发效率,使程序员能够更快地完成任务。然而,当工作量从修复单个错误或自动生成文档的细小环节,逐渐过渡到让AI承担整个功能模块的开发时,问题便开始显现。这种把工作“委托”给AI的行为,引发了一种被称为“AI委托困境”的难题。理解这一困境,有助于开发人员更有效地利用AI工具,同时避免在工作流程中陷入因失控或低效导致的反复修改与返工。AI委托困境的核心在于设计精准(Design Fidelity)、提示效率(Prompt Efficiency)和输出可用性(Output Usability)这三者之间的权衡。
设计精准指代码的功能和结构必须精准反映开发者的意图,而非盲目依赖AI的假设。提示效率意味着开发者通过简洁、高效的指令就能快速引导AI生成所需代码。而输出可用性则强调生成的代码能直接被使用,几乎无需额外修改。在实际操作中,这三者只能同时优化其中两个,而不得不牺牲第三个。这种三角权衡犹如经典的“快、好、省”难题,让开发者在不同目标中做出取舍。选择设计精准与输出可用性,往往意味着需要耗费大量时间撰写详细且复杂的提示,挑战提示效率。
若重视提示效率与输出可用性,开发者则常常不得不接受AI自行做出的设计决定,导致设计不尽人意。而若聚焦设计精准和提示效率,则必须准备好对生成结果进行大量人工修改,降低了输出可用性。此种困境并非偶然,而是深植于当前大型语言模型的工作机理之中。LLM依赖海量训练数据,通过统计概率预测下一步输出,从模式中推断生成结果。虽然强化学习等技术增强了输出对人的“可接受度”,但AI并不真正理解项目细节、架构约束或业务逻辑。这种“能说会道却无知情”的特质,使得模型的代码具备貌似合理,却在实际中存在缺陷、误用不存在的函数,或错误引入虚构库的隐患。
此外,AI的“工作记忆”局限于上下文窗口,且无法像人类一样积累新知识,缺乏对项目历史、团队约定、非显性需求及安全规范的持续了解,导致输出内容往往泛泛而无深度契合项目需求。此情景下,AI的输出更多表现为“模仿式”创作,缺乏对细节的把控和长期学习能力。为了应对这种根本性限制,开发者必须根据任务性质和需求权衡三者。例如,当需快速原型时,优先保证提示效率与输出可用性,接受AI自作主张的设计,适用于探索阶段,但不适合直接投产。若需快速获得设计贴近且具概念性的起点,则保持设计精准和提示效率,视AI为辅助脑力激荡助手,准备进行大量人工打磨,适合项目初期构思。追求产出直接符合设计与功能需求时,则需投入大量时间编写复杂提示和多轮迭代,不惜牺牲提示效率,获得接近理想的输出,适合成熟阶段的功能开发。
此外,对于大型且复杂的项目,尤其是涉及深度集成或已有庞大代码库的情况,完全委托给AI往往弊大于利。此时,最好限制AI工作范围,避免大规模重构,而将AI用作辅助处理细粒度任务,确保人类开发者主导整体架构和流程,把控质量与一致性。换言之,AI工具最适合作为开发流程中的增效器,而非全权代理。认识到AI委托困境,开发者能够在使用AI时保持理性预期,避免被“魔法般的快速生成”冲昏头脑。现实中,成功利用AI助力开发产品的关键,在于明确任务需求、合理分配AI参与度,以及理解不同策略下带来的权衡效果。随着AI技术不断发展,未来或许会出现对上下文更长记忆、更深度理解能力的模型,缓解当前的局限性,但现阶段,AI委托困境仍是不可绕过的挑战。
综合来看,AI辅助编程彰显了人工智能与软件工程结合的巨大潜力,但其委托工作方式的限制难以忽视。面对设计精准、提示效率与输出可用性的三角权衡,开发者需要根据项目实际需求灵活选择策略,或在必要时绕开委托路径,保持人工控制。唯有如此,才能既发挥AI提升效率的优势,又保障代码质量与项目目标的精准实现。在软件开发进入智能化时代的转折点,深入理解AI委托困境,有助于企业和开发者制定科学合理的AI应用方案,避免盲目依赖,稳步迈向生产力革新新高度。