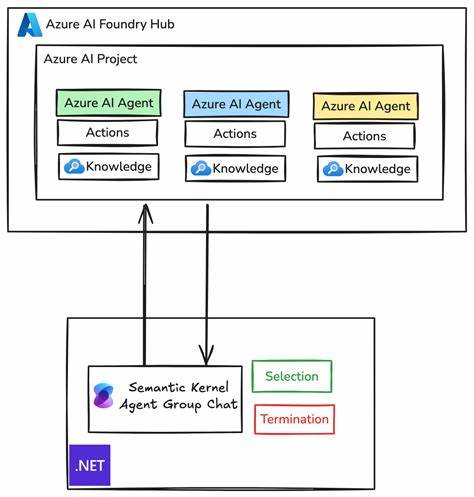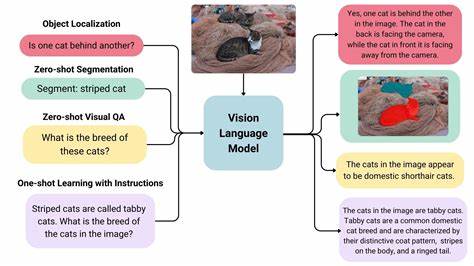
随着人工智能技术的日益进步,视觉语言模型(VLM)因其强大的图像理解和语言处理能力,正在改变我们与环境互动的方式。传统室内定位依赖于蓝牙信标、Wi-Fi信号甚至专用硬件,成本高且部署复杂,限制了其普及和应用范围。近期,一种融合了VLM技术与现有室内地图的全新室内定位方案引起了广泛关注,它通过分析用户拍摄的照片内容,结合地图信息,实现定位的快速原型设计和应用探索。 这一创新思路的核心是在已有的室内平面图基础上,利用视觉语言模型识别照片中显示的店铺标牌或其他语义信息,然后将这些标识与地图中的位置数据进行匹配,从而推断出拍摄者的可能位置。相比传统基于信号强度的定位系统,这种方法不依赖于额外硬件,极大降低了部署成本和复杂度。此外,通过对照片多方向的采样,系统还能估计用户的朝向,提高定位的准确性和实用性。
室内地图通常具有标注走廊、商铺、卫生间等关键区域的信息,这些元素为基于视觉的定位提供了极佳的语义参考。通过开发专用的图像注释工具,用户可以快速对地图中的不同区域进行标记,形成结构化数据集作为定位辅助。接下来,通过预处理函数,系统遍历每个走廊点,模拟用户从不同角度看向周围可见商铺的情况,构建“可见商铺”字典,为实际定位提供丰富的匹配候选。 针对用户拍摄的照片,视觉语言模型则发挥关键作用。它分析照片中出现的商铺标识,通过调用先进的图像识别API,识别出店铺名称。随后,系统将识别结果与之前处理的地图数据进行比对,通过集合匹配的方法,筛选出最有可能的位置点。
实验结果显示,该方法能够将用户的实际位置精确映射到地图中的黄色圆点区域,准确度令人惊喜。 尽管目前的案例侧重于单张照片识别,且需照片中具有显著的商铺标志,但实验证明了该方法在室内定位领域的巨大潜力。随着技术的成熟,未来还可引入视频连续帧和手机传感器数据,通过粒子滤波等算法进一步提高定位的稳定性和准确性。甚至可以构建专门的训练数据集,使用深度学习模型实现从图像到位置信息的端到端映射,推动应用走向工业化和规模化。 此项基于视觉语言模型的室内定位技术还为增强现实(AR)设备的发展打开了新思路。用户佩戴AR眼镜时,结合环境图像与地图语义,可以在视觉层面直接获得导航指引,极大提升室内导航体验与效率。
同时,对于物流机器人、智能导览等机器人应用场景,这套技术也具备广阔的应用前景。 自然,当前阶段该技术仍处于原型探索阶段,存在定位精度受限、对环境依赖较强等问题。商铺标志被遮挡、环境光线复杂等因素均可能影响识别效果。此外,系统依赖于现有地图的准确性,地图更新的延迟也会影响定位结果的时效性。如何融合更多传感信息,提升模型的鲁棒性,仍是未来研究的重点方向。 这一创新的室内定位实践也体现了软件发展的新趋势,即通过语言与视觉模型的“胶水代码”快速搭建专用工具,轻松实现复杂功能。
这种快速迭代与开发的能力,将加速AI技术在各行各业的广泛落地与应用,为生活带来更多便利和可能。 总的来说,视觉语言模型结合结构化室内地图数据,实现基于照片的定位技术,展示了数字化室内导航的新方向。它不仅降低了部署门槛,提升了用户体验,也为AR与智能机器人应用提供了坚实技术基础。随着技术的不断进步和应用场景的不断丰富,相信基于VLM的室内定位未来将迎来更加广阔的发展空间,真正实现用视觉语言让空间“活起来”。