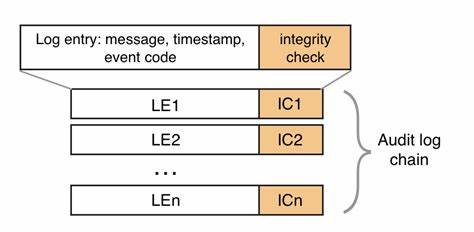
大型语言模型(LLM)作为人工智能领域的重要组成部分,正迅速改变着人们的工作和生活方式。无论是自动化文本生成、智能客服,还是复杂的信息检索和辅助决策,LLM的应用场景日益丰富。然而,随着其应用的深入,如何保证每一次调用的可信度、安全性和合规性成为亟待解决的问题。Traceprompt正是在这一背景下诞生的创新工具,通过防篡改的日志机制,为每一次LLM调用建立起不可篡改的记录体系。 大型语言模型的调用通常涉及复杂的数据处理和权限管理,尤其是在金融、医疗、法律等对安全和隐私要求极高的行业,任何调用记录的缺失或篡改都可能带来严重的法律和商业风险。传统的日志系统往往依赖中心化服务器存储,容易受到恶意篡改或数据丢失的威胁,难以满足多方对数据安全的需求。
Traceprompt针对这一痛点,通过采用链式数据结构和加密技术,将每次调用的详细数据按时间顺序记录下来,并利用密码学手段确保日志内容的不可篡改性和可验证性。 Traceprompt的设计理念强调操作的透明度和责任的可追踪性。每当LLM进行一次调用,Traceprompt都会自动捕获该请求的输入、输出、时间戳及相关上下文信息,并将这些数据生成一条日志记录。通过对日志内容进行哈希和签名处理,确保任何试图修改日志数据的行为都能被即时发现。此外,Traceprompt还支持多节点分布式存储,使日志数据不依赖于单一存储点,进一步提升系统的抗篡改和抗破坏能力。 在具体应用中,Traceprompt能够提供详尽的调用轨迹,帮助开发者和运营人员分析模型行为,优化模型性能,及时发现异常情况。
对于合规审查和内部安全管理,Traceprompt的防篡改日志为企业提供了有力的证据支持,满足各类法规对数据完整性和透明性的严格要求。同时,由于Traceprompt以自动化、无缝的方式集成在LLM调用流程中,极大地减轻了用户的运维负担,提高了使用体验。 除了安全和合规方面的显著优势,Traceprompt还推动了行业间的合作与创新。通过对调用日志的标准化记录,不同团队和组织能够共享和分析LLM的使用数据,促进模型改进和应用场景的拓展。此外,Traceprompt的开放设计理念支持多平台、多语言环境,适配各种主流LLM框架,有助于构建生态系统的互联互通。 要理解Traceprompt的重要性,不妨将其视为LLM调用的“数字指纹”。
它不仅是技术层面的记录工具,更是信任机制的基础。随着人工智能应用场景的不断复杂化,用户、开发者、监管者对数据和模型行为的透明度需求不断提升,Traceprompt这样的防篡改日志技术将成为AI领域不可或缺的组成部分。 未来,随着区块链、零知识证明等技术的进一步融合,Traceprompt有望实现更高级别的安全保障和隐私保护。同时,结合大数据分析和可视化工具,它也将成为AI伦理和治理的重要助手,推动行业走向更加健康和可持续的发展路线。 总之,Traceprompt不仅为每一次大型语言模型调用提供了防篡改的日志保障,更为整个AI生态系统注入了可信任的基因。在智能时代,保障数据的完整性和操作的透明度,是实现技术与责任共赢的关键。
Traceprompt的出现,恰恰回应了这一时代呼唤,为构建安全可靠的人工智能应用奠定了坚实基础。