对话式界面,作为人工智能和人机交互技术的交汇点,近年来随着大型语言模型的快速进步而迅猛发展。人们对聊天机器人和智能助手的期望不断提高,然而当前许多对话系统的用户界面仍停留在传统的文本框架和超链接的层面,缺乏足够的创造力和人性化。尽管背后强大的技术支持令人惊叹,但用户体验却往往未能达到理想状态。这种现状反映出一个关键问题:我们倾注大量精力完善对话系统的“大脑”——即语言模型,却忽略了对话“灵魂”的打造,即如何让界面和交互本身更加贴近人类的自然交流方式。语言是构成对话的基本元素,但对话本身是一门复杂且讲究艺术的沟通方式,融合了语境、情感、文化和非语言信号。人与人之间的对话极为流畅,节奏明快,换句话说,日常交流看似随意,实则遵循着一套细微而严格的规则。
这些规则包括轮流发言的时机、语音的起伏、停顿的长度、语气的变化,甚至体态语言的配合。人工智能若想打造“人味十足”的对话体验,必须对这些细节给予高度关注。研究显示,人类在对话中轮流发言的间隔平均在200毫秒左右,这比人的眨眼速度还快。稍有延迟,就会影响交流的流畅度和情感表达。比如,一个快速肯定的回答和缓慢拖沓的犹豫,传递的信息截然不同。此外,不同文化对对话节奏的期望也存在差异。
如日语对话中几乎没有停顿,声音甚至重叠,而丹麦语则偏好更长的间隔。良好的对话式系统必须能灵活适应这些文化差异,调整响应的时机和方式,体现对用户背景的尊重和理解。为了实现更加自然的对话交互,设计者需要关注“预测、规划和时机”这三大核心能力。预测即在用户话语接近尾声时,准确判断发言即将结束,提前准备下一句回应;规划涉及清晰明确下一步对话内容,确保上下文连贯且契合用户意图;时机则是精确把握回应时的节奏和停顿,让回复听起来顺畅且不突兀。完整的对话体验还离不开对人类常用“对话信号”的捕捉和反馈,如眼神交流、呼吸变化等自然信号在人机交互中对应为语音的声调变化、停顿以及语气词(如“嗯”、“你知道吧”)。设计者可利用语音分析技术,实时捕捉这些信号,进而决定合适的发言时刻,体现“礼貌的打断”或“顺畅的接力”。
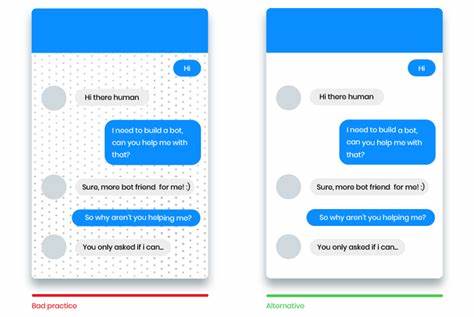
另外,对话过程中的“修复机制”也至关重要。现实交流时常会出现误解、表达模糊或信息不完整的情况,人类会自如地通过提问、重复确认、改写等手段来澄清。优秀的智能对话系统应当模仿这种行为,使用礼貌的澄清请求(如“抱歉,能再说一遍吗?”),或通过复述确认以显示理解(如“您是说……对吗?”),避免机械地回答“我不理解”,而是提供进一步的引导和选择,重建对话的桥梁。这不仅提升系统的可靠度和用户信任感,也让交流显得更加人性化和温暖。除了语音对话,文本聊天也存在类似的对话信号,但表现形式不同。比如文本中的短语、省略号、表情符号和排版结构,都暗示说话者的情绪和意图。
系统需要结合上下文,识别这些信号,从而进行合理回应和内容关联,防止出现话不投机或频繁跳跃话题的尴尬。文化差异是设计对话式界面时不可忽视的重要因素。不同文化对于说话节奏、打断礼仪、反馈方式和对话方式的偏好迥异。一个面向国际市场的智能助理应具备动态调整能力,既能够遵循本地文化的自然交互规则,也能尊重多样化用户的沟通习惯。技术实现层面,设计人员需配备端到端的实时语音识别、情感分析、语义理解与生成模块。同时,通过流式语音识别实现边听边回应,减少明显停顿,在用户尚未完全说完时即开始构思回答,大幅提升交互流畅度。
视觉界面也能辅助手势、光圈等视觉反馈,使用户对系统的“倾听”状态有明确感知,降低误解概率。值得关注的是,目前大多数商业聊天机器人更多强调语言模型的知识和推理能力,但忽视了对话的韵律性和互动感,导致交互体验机械、单调。未来发展应重视对话动态特性的建模,深入挖掘语速、语调、停顿长度与意图之间的关系,使系统具有“节奏感”和“灵活性”,从而激发用户更长时间的活跃参与。展望未来,随着多模态交互技术的兴起,摄像头等感知设备将融入对话系统,捕捉用户表情、手势和环境信息,结合智能语音,实现更加丰富且自然的人机交流。这不仅令对话式界面更加生动,也赋予系统深度理解用户状态和情感的能力。总而言之,对话式界面的设计是一门复杂而精妙的艺术,需要工程师和设计师综合考虑语言学、心理学、人类学等多学科的研究成果,尊重人类沟通的规律和文化差异,创造出真正“活起来”的智能助手。
只有如此,未来的聊天机器人才能脱离冷冰冰的代码束缚,成为人们生活中值得信赖与依赖的合作伙伴,推动人工智能迈向更高的智慧与温度。