近年来,随着人工智能技术的迅猛发展,大型语言模型(LLM,Large Language Model)因其惊人的语言生成能力,成为科技界和大众关注的焦点。很多人对这些模型赋予了近乎魔法般的期待,认为它们能够取代人类的思考、写作甚至创造力。然而,透过表象,我们应当清晰地认识到,这些模型究竟是什么,它们的局限在哪里,以及我们应该怎样理性使用它们。 大型语言模型本质上是依托于海量数据和复杂算法的一种统计型“文字机器”。它们通过分析大量文本数据,学习词汇之间的概率关系,从而在给定上下文的前提下预测下一个最可能出现的词语。这一过程并非真正的理解或思考,而是纯粹的概率计算。
换言之,LLM并不拥有意识或理解能力,只是高度复杂的模式识别系统。 这种技术带来的第一层幻象是“语言的错觉”。由于人类的大脑长期以来习惯将合乎逻辑且连贯的文本视为背后有人类思维的结果,当机器输出的文字呈现类似于人类表达的风格时,人们很容易误以为这些文字是有意味、有思想的产物。这种心智偏差让很多用户对LLM的能力产生了过度期待,甚至将机器人格化,误认为它们拥有感情、判断力和智力。 实际情况是,LLM完全无法构建语义的深层次意义,没有真正的“理解”或“意图”。它们的输出纯粹基于统计学和语言模式的模拟,这就解释了为何大型语言模型在遇到复杂现实问题或者需要推理判断时,常常会出现错误甚至荒谬的回答。
比如在某些实际测试中,很多政府网站的聊天机器人无法正确回答基本信息,如节假日安排或者税收减免等,甚至在无障碍服务方面严重不合格,影响视障人士的使用体验。 此外,LLM的训练数据存在偏见和不完整性,这导致输出结果往往带有某种程度的偏见和误导信息。由于模型依赖于人类创造的内容,任何带有偏见、错误甚至虚假信息的文本都可能被模型“学习”并反映在其回答中。虽然研发人员尝试通过各种技术手段减少这些问题,但偏见和错误无法完全消除,因而必须有人类监督和校验来确保内容的准确和合规。 另一个不得不关注的问题是“自动化与思考的关系”。不论市场营销和媒体如何吹捧AI能大大提高效率、解放人类劳动,实质上当前的LLM更多是在协助人类完成文字输入和编辑等技术性环节,而非替代思考和创造。
写作等认知活动涉及复杂的想法组织、情感表达和逻辑推理,这些是现有模型无法企及的高度人类专属能力。恰恰相反,盲目依赖语言模型产出的文本,极有可能造成思维的退化和写作能力的下降,因为人们会习惯性放弃审慎的分析和创造,反而滋长“自动化懒惰”。 这也引发了对通俗传播领域的思考。作为传媒和沟通专业人员,应当警觉到机械生成文本的局限,不应盲目追随技术炒作,更不能沦为“自动写作”的帮凶。与其助长伪创新和碎片化内容,不如引导公众理解科技的本质,提升批判性思考能力和创造力,推动内容质量和传播效果的提升,实现人机协作的最大化价值。 市场营销对LLM的包装也是一面镜子。
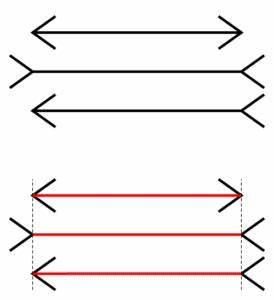
人工智能产品往往被赋予“智能”、“革命性”的标签,激发出稀缺感和恐惧感(FOMO),轻易俘获缺乏专业认知的用户。对技术不了解或者缺乏科学基底的受众,很容易陷入“魔法幻象”,忽视技术底层的统计本质。正如光学幻觉让我们感知到不存在的图像,语言模型制造的“语义幻觉”让人误以为机器具有智慧。 这其中,女性化的拟人界面设计、拟人的名字以及模拟打字的动画等细节,更强化了人的情感投射和信任感。然而,这只是一种营销策略,不应掩盖机器的本质——一个没有理解能力的概率计算器。 对未来的思考,需要回归对大脑和语言本质的理解。
人类的语言能力是在长期进化过程中建立起来的复杂认知活动,涵盖情境感知、多模态经验和文化背景。这远非当下的语言模型能够企及。即使是最强大的LLM,也只能作为辅助工具,帮助校对、提供灵感或加速文稿处理,绝不可被视作真正的“思考伙伴”。 值得欣慰的是,科学界、教育界和法律界对LLM的认知普遍保持理性。学者们强调认知科学的视角,提出“AI不是真正的智能”,并将重点放在人类批判性思维和创造性培养上。公众应当谨慎使用这类技术,明确它们的边界,避免被“表象”的流光溢彩所迷惑。
总结而言,大型语言模型是一场精妙的“派对魔术”,它利用了人脑对语言和沟通的进化认知机制,制造出仿佛会“思考”的文字假象。但归根到底,它们不过是复杂的文本预测器,缺乏真正的理解和判断。我们应当摒弃盲目崇拜,提升对语言生成技术的科学认知,用批判性眼光审视其优缺点,合理借助其优势,同时保持人类的创造力和思考能力。只有这样,技术才能真正为社会服务,而非成为思维的绊脚石。 人类的大脑是无可替代的宝贵财富,没有任何机器可以复制人类的直觉、情感、思考和创造。未来,训练人脑,提升认知能力,比训练机器更为重要。
我们应当重新认识写作和交流的价值,将科技作为辅助而非替代力量,推动文明与智慧的不断进步。