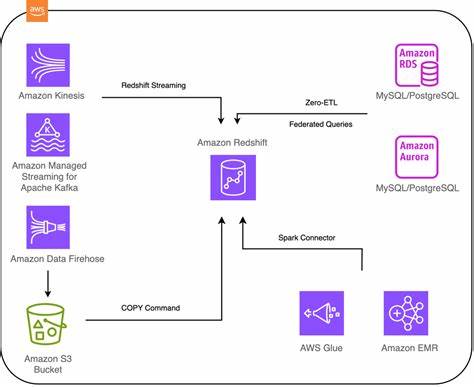
随着大规模向量检索成为生成式 AI、语义搜索和推荐系统的核心,向量存储的内存成本与查询性能成为工程实践中的两个关键约束。Redisearch 在其 Redis Query Engine 中引入基于 Intel SVS 的 SVS-VAMANA(结合 LVQ 与 LeanVec)为向量量化与降维提供了新的思路,目标是在不牺牲检索精度的前提下显著降低内存占用并提升查询吞吐量与延迟表现。本文从技术原理、性能影响、使用场景与部署建议等角度,系统梳理这些新功能的价值与取舍,帮助工程团队在生产环境中作出更理性的选择。 向量检索面临的现实问题值得关注。常见的文本或多模态嵌入往往具有数百到数千维度,若以单精度浮点数(FP32)存储百万级别的向量,内存占用会迅速膨胀至数十到数百 GB。对于基于图的近似最近邻(ANN)算法,如 HNSW 或 Vamana,除了向量本身的存储外,图结构与索引元数据也占用显著内存。
内存不仅影响云费用,还决定了系统能否在给定硬件上实现低延迟与高并发。因此有效的向量压缩与降维显得尤为重要,而关键在于在压缩率与检索质量之间寻找最佳平衡点。 SVS-VAMANA 的引入结合了图检索算法与数据感知的量化技术。Vamana 本身是一种图基检索算法,类似 HNSW,但采用单层图结构并通过可调节的剪枝策略控制边数。SVS-VAMANA 的创新在于将 Intel 的 LVQ(Locally-adaptive Vector Quantization)和 LeanVec 压缩技术与 Vamana 紧密结合,从而实现对图索引与向量数据的联合优化。与传统的产品量化(PQ)或全局标量量化(SQ)相比,LVQ 与 LeanVec 更善于在内存受限与高吞吐场景中保留高精度检索能力。
LVQ 的核心思想是对每个向量单独进行局部归一化后再做标量量化。传统的全局或按维度的量化往往无法充分利用可用量化区间,导致精度下降或浪费比特位。LVQ 通过每向量自适应的归一化边界,使量化后的数值分布更接近均匀,从而在相同位宽下获得更高的表示精度。LVQ 的解压开销极低,设计上支持在线、即时距离计算,使得在检索时可以直接对量化表示做距离估算而无需频繁访问原始浮点向量,这一点对基于图的随机访问模式尤为关键。 LeanVec 则在 LVQ 的基础上先做线性降维,再对降维后的向量应用 LVQ。降维步骤大幅减少了后续计算与内存传输的代价,尤其对高维(例如 768 维及以上)嵌入效果显著。
LeanVec 使用两级策略:第一层对降维向量进行量化用于候选检索,第二层对原始高维向量的残差或高维表示再做 LVQ 以用于重排序。两级编码确保在大多数查询中只需访问第一层即可快速返回高质量候选,而在需要更高精度时再触发第二层重排,从而在速度与质量之间取得折中。 这种两级量化在工程上带来几个重要好处。首先,它允许在常规查询路径中使用紧凑表示,显著降低内存带宽消耗,进而提升并发吞吐量与降低 p50/p95 延迟。其次,第二级残差编码为高精度场景保留了可选提升途径,无需在常规访问中承担高成本。实验数据显示,LVQ 与 LeanVec 在索引层面可实现约 51-74% 的内存压缩,而总内存占用通常可降低 26-37%,在保持 HNSW 级别精度的同时还能提升查询 QPS。
有趣的是,LeanVec 在高维向量上的收益通常高于 LVQ,使其更适合 768 维及以上的嵌入。 性能优化并非单纯的压缩算法选择,还依赖于实现细节。Intel 在 LVQ 的内存布局与 SIMD 访问上做了深度优化,例如 Turbo LVQ 将向量维度重排为适合矢量化加载的布局,能够用极少的指令展开多个维度,极大提高距离计算的效率。因为基于图的搜索通常受到内存带宽限制,这类低开销解压与向量化友好的内存布局,能把压缩带来的内存节省直接转化为更高的吞吐量与更低的延迟。 在实际部署时,硬件平台是决定最终效果的重要变量。SVS-VAMANA 在 x86 平台(尤其 Intel)上能发挥最优表现,借助 Intel 的 SVS 库实现 LVQ 与 LeanVec 的加速。
在 AMD x86 平台上若无法使用 Intel 优化实现,系统会回退到 SQ8 等通用量化策略,仍能取得一定收益但不及 Intel 优化水平。ARM 平台上目前 SVS-VAMANA 的上传与压缩优化尚不完善,构建索引的开销可能显著高于 HNSW,因而在标准化采用 ARM 的集群上,HNSW 依然是更稳妥的选择。简单地说,如果基础设施是 x86,优先考虑启用 SVS-VAMANA 与 LeanVec;如果是 ARM,建议继续使用 HNSW 或在验证后谨慎启用回退的量化方案。 任何压缩方案都存在输入侧的折衷。SVS-VAMANA 的代价主要体现在索引构建与写入延迟。量化与降维需要额外的计算,LVQ 在某些数据集上可能导致索引构建时间比 HNSW 长 2.6 倍,而 LeanVec 在部分情形下上传速度甚至可略优于 HNSW。
ARM 平台上的构建开销尤为明显,可能出现显著的性能回退。因此在选择压缩策略时,需要综合考虑写入吞吐与查询延迟的权衡。对以读为主且查询性能要求高的线上服务,压缩带来的长期运行成本下降通常值得在离线或异步流程中承担更高的构建开销。Redis 的异步索引架构恰好为这类权衡提供了便利:主线程仅做缓冲与标记,后台工作线程异步完成压缩与图维护,从而将构建开销与前端请求响应解耦,使系统在高写入负载下依旧保持响应性。 在工程使用层面,Redisearch 将 SVS-VAMANA 的压缩选项集成到向量字段定义中,开发者只需在 FT.CREATE 的 VECTOR 字段中指定算法与压缩参数即可启用。例如可以在索引定义中写入 embedding VECTOR SVS-VAMANA 6 COMPRESSION LVQ8 TYPE FLOAT32 DIM 768 DISTANCE_METRIC COSINE 这样透明的一行配置即可在索引构建过程中触发量化与降维流程。
查询端对应用开发者保持无感,检索 API 与语义保持一致,所有量化与解压逻辑在服务器端完成。对 Redis Open Source,若要在非 Intel 平台或开源版本启用特定优化,社区与文档中提供了触发优化或安装 SVS 的指南。 选择适当的压缩策略与参数需要结合具体的嵌入类型与应用场景。文本嵌入通常位于 384 到 1536 维之间,属于语义浓缩且较规则的分布,LeanVec 在高维文本嵌入上常带来优异效果。图像嵌入维度常超过 1024,数据噪声与分布差异更大,LeanVec 的降维有助降低噪声敏感性。多模态嵌入则混合了文本与视觉特征,可能需要更保守的量化或专门的降维策略。
对于低维或对延迟极敏感的在线检索场景,LVQ 的单向量量化与低解压开销可能更适合。总之"在 768 维及以上优先 LeanVec,小于 768 维优先 LVQ"是一个实用的经验法则,但最终应通过数据集级别的压缩试验与精度-吞吐量曲线寻找最合适的配置。 调优层面有几个关键参数值得关注。SEARCH_WINDOW_SIZE 在 SVS-VAMANA 中对应 HNSW 的 EF_RUNTIME,需要在查询时根据精度目标进行校准。GRAPH_MAX_DEGREE、CONSTRUCTION_WINDOW_SIZE 等构建参数影响索引质量与构建成本。对于 LeanVec,还应关注 REDUCE 参数,它定义了降维目标,典型的性能优化配置可能将降维目标设为原维度的四分之一,在 DBpedia 这样高维数据集上能带来显著上传时间与查询吞吐量改进。
建议在构建索引前借助 benchmark 工具进行校准,以在所需精度(例如 0.95)与吞吐量之间达成合理折中。 实践案例与基准结果进一步印证了理论优势。在多个数据集与 CPU 平台的测试中,SVS-VAMANA 在 FP32 数据上对 Cohere(768 维)与 DBpedia(1536 维)等中高维任务表现出了显著的吞吐量与延迟优势,在同等精度下查询吞吐量最高可提升至 1.44×,p50/p95 延迟可降低 40% 至 60%。在 LAION(512 维)等较低维度数据集上,收益相对较小,但仍能带来可观的内存节省。实际部署时应关注压缩后索引内存减少对于云成本的直接影响,特别是在百万级向量规模以上,26-37% 的总内存节省足以显著降低长期运行成本或扩大单机可承载的向量数量。 面向未来,Redisearch 与 Intel 的合作将继续扩展压缩与加速覆盖面,包括对更多索引类型的量化支持、对异常分布与跨模态查询的 query-aware 降维策略、以及对多向量记录的高效支持。
对 ARM 平台的优化也是重点方向之一,目标是缩小不同 CPU 家族间的性能差距,使得压缩方案在更多云实例与本地部署上都具备实用性。 对工程团队的建议是,从小规模基线开始实验,先在一类代表性嵌入上评估 LVQ 与 LeanVec 的精度-吞吐曲线,测量索引构建时延与写入吞吐的影响,再决定是否在生产集群上全面采纳。对于以读为主且查询延迟要求严格的服务,SVS-VAMANA 在 x86 环境下通常能带来显著回报;对于写入密集或基于 ARM 的方案,则需谨慎评估或暂用 HNSW 直到相关优化到位。 總結而言,Redisearch 的新向量量化能力通过将 LVQ 与 LeanVec 引入图索引检索链路,为海量嵌入场景提供了一条在内存占用、吞吐量与检索质量间取得平衡的可行路径。合理地选型与调优能够在不降低用户体验的前提下大幅压缩运行成本,并为大规模 AI 应用提供更灵活的基础设施选择。 。