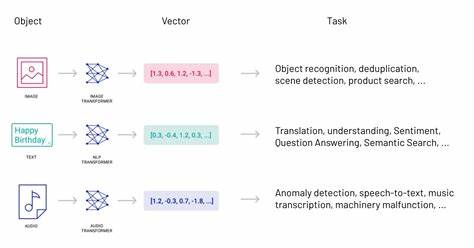
在当前人工智能浪潮推动下,基于向量的检索系统,尤其是融合检索增强生成(Retrieval-Augmented Generation,RAG)技术的应用正逐渐普及。它们通过高效的向量嵌入(Vector Embeddings)实现海量数据的语义理解和快速检索,极大提升了信息获取效率。然而,安全研究的最新进展揭示了一种前所未有的威胁形式——借助向量嵌入进行隐蔽的数据外泄,这便是VectorSmuggle的核心所在。VectorSmuggle是一个以展示向量嵌入隐蔽数据泄露技术为目标的开源项目,通过多种隐写技术将敏感信息藏匿于看似正常的向量空间中,绕过传统数据防泄漏(DLP)系统检测,为攻击者打开了一条隐秘数据传输的“后门”。这不仅对企业数据安全构成挑战,也给AI安全领域提出了新的课题。理解VectorSmuggle的工作机制,对于构建更加坚固的防护体系至关重要。
向量嵌入技术基础上,数据信息被转换为高维向量,该过程本质上保持了文本或数据的语义特征。VectorSmuggle利用这一特点,将隐写技术(Steganography)应用于向量空间,注入微小的扰动或结构变换,如噪音注入、旋转变换与碎片分散等,从而将敏感数据融入正常向量中。这些载有隐秘信息的向量经过数据库存储与检索操作后,攻击者可通过专门设计的解码器精确恢复出原始敏感内容。这样一来,即使受到严格访问控制和传统防护,敏感信息仍可能被悄无声息地“走漏”。VectorSmuggle支持超过十五种主流文档格式,涵盖PDF、Office文档、邮件存档及数据库导出文件,充分模拟现实企业环境中多样化的数据载体。通过测试,可实现跨模型、多技术的隐写组合攻击,进一步增强隐蔽性与数据承载量。
该项目还集成了“行为伪装”(Behavioral Camouflage)和“流量模拟”(Traffic Mimicry)功能,使攻击活动表现得更加符合正常业务流程,降低异常检测系统的告警概率。VectorSmuggle在技术层面体现出高度的复杂性和隐蔽性,其设计重点落在全流程攻击的模拟与重放。从文档加载、向量隐写、数据库存储,到查询恢复与风险评估,每一个环节都有对应模块支持,为安全研究人员提供了一个强大的实验和防御验证平台。在实际应用中,向量数据库常见于大规模信息检索及问答系统,然而由于嵌入向量本身无需明文传输,传统数据损失防护工具难以监测其中潜藏的语义信息泄露。VectorSmuggle正是针对此缺口,通过隐写技巧填充向量维度,突破现有安全屏障,使得敏感信息得以潜伏在正常数据流中,隐匿性极高。为防范此类风险,首先需要加强对向量空间的统计分析和异常检测。
通过基线建立与特征挖掘,可以识别出潜在的异常嵌入模式。例如统计性签名、空间分布检测及多模型一致性验证等手段,有助于及时发现异常向量。同时,强化行为分析能力也是关键。利用机器学习模型监控用户操作频率、访问模式和流量特征,识别可能的伪装行为,并结合流量模拟特征提升异常识别准确率。此外,数据清理与敏感内容过滤应在嵌入前完成,最大程度减少敏感信息进入向量库。建立严格的权限管理与访问控制,是防止内部威胁渗透的重要环节。
企业应部署完整的审计日志体系,对所有嵌入与查询操作保持透明,方便追溯和事后分析。VectorSmuggle的出现,促使AI安全研究社区重新审视基于向量的RAG系统中的安全防护盲区。其不仅暴露了潜在的内部威胁,也映射出现有安全方案针对新型攻击的不足。未来,随着向量数据库及大规模语言模型(LLM)应用的进一步深化,相关的安全防范体系必将持续演进。研究人员和从业者需要加强跨领域合作,结合数学、统计学和行为科学的多维度方法构建综合防御体系。总体而言,VectorSmuggle不仅是一个技术演示工具,更是对当前AI时代数据安全的一次深刻警醒。
它提醒我们,在利用先进人工智能工具提升效率的同时,必须同步构筑起相应的安全防线,才能真正保障企业数据资产和用户隐私的安全。面对日益复杂的安全威胁,秉持预防为先、持续监控和积极响应的原则,方可防止“隐形数据走私”带来的风险,确保人工智能技术走得更稳更远。