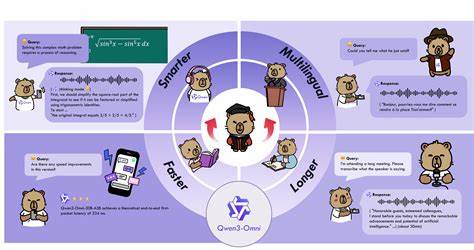
近年来多模态人工智能快速发展,但在文本、图像、音频与视频四大模态上同时保持顶尖性能一直被视为极具挑战的目标。Qwen3-Omni以一种统一的技术路线首次实现了在四类模态上不逊于同尺寸单模态模型的表现,标志着多模态模型从能力折中向"全能不妥协"迈出关键一步。本文从技术细节、性能评估、应用前景及工程实现角度,系统解读Qwen3-Omni的创新点与实际价值。Qwen3-Omni在2025年9月发布的技术报告中展示了其在36项音频与音视频基准上的卓越结果,在开源阵营中实现了32项最佳表现,并在22项上取得整体SOTA,甚至超越了多个封闭源强模型如Gemini-2.5-Pro、Seed-ASR与GPT-4o-Transcribe,这一成绩背后是若干关键架构与优化策略的组合。Qwen3-Omni的核心思想是Thinker-Talker MoE架构,它将"思考(Thinking)"与"表达(Talking)"两个能力模块明确区分并协同工作。Thinking模块专注于跨模态推理与长上下文的多模态整合,能够对来自文本、图像、音频与视频的输入进行显式的多步骤推理与逻辑建模,以增强复杂任务的可靠性与可解释性。
Talking模块则负责将高阶语义或感知结果转换为自然文本或实时语音输出,并在语音生成方面采用多码本离散编码与流式生成策略,显著降低了合成首包延迟,满足实时交互需求。在感知层与表示学习上,Qwen3-Omni实现了统一的跨模态表征空间,允许同一套参数化结构同时处理语言、静态图像、连续音频与视频帧序列。模型的设计强调模块化与参数高效共享,使得在保持单模态性能的同时,避免了常见的多模态干扰或能力互相冲突的问题。通过大量跨模态与单模态混合训练,模型学会在不同任务之间迁移表示能力,从而在单模态基准上匹配或逼近同尺寸单模态兄弟模型的成绩,而在音频相关任务上更是实现了显著领先。语音合成与流式交付是Qwen3-Omni的一大工程亮点。传统高质量语音合成往往依赖连续波形生成或复杂的扩散过程,难以做到从首帧开始就低延迟输出。
Qwen3-Omni的Talker采用多码本的离散语音编码方案,将连续音频映射为一系列离散代码(multi-codebook),并用自回归方式预测这些代码序列。多码本设计提升了离散表示的表达力,使得在码本空间内可以高效表达细腻的语音细节。为了解决基于扩散的高计算成本问题,团队用轻量级的因果卷积网络(causal ConvNet)替代了传统的分块扩散方法,从而实现在无需等候整块上下文的情况下就能开始生成首个语音帧。工程化结果是,在冷启动场景下理论上实现了234毫秒的端到端首包延迟,这对实时通话、语音助手与在线串流合成具有重要意义。在多语言与多任务能力上,Qwen3-Omni同样表现出色。模型支持119种文本交互语言,语音理解覆盖19种语言,语音生成支持10种语言。
这种广覆盖能力使得单一模型能够服务全球化的产品需求,同时简化了多语言部署的工程复杂度。为了强化音频相关的语义生成能力,研究团队进一步从Qwen3-Omni-30B-A3B微调得到Qwen3-Omni-30B-A3B-Captioner,一个专注于音频描述与音频字幕生成的模型。Captioner在音频标注任务上展现了低幻觉率与细致描述能力,填补了科研社区中通用音频字幕/描述模型的空白。性能评估方面,Qwen3-Omni在36项音频与音视频基准测试上获得了卓越结果。开源SOTA覆盖32项,整体SOTA达到22项,显示出在语音识别、语音翻译、音频分类、音频事件检测与语音转写等任务上的强劲能力。尤其在对比封闭源模型时,Qwen3-Omni在若干场景下实现了一定幅度的领先,证明了开源研究与工程创新能够在复杂多模态任务上达到工业级水准。
从工程实现的角度看,Qwen3-Omni的成功并非单一创新所致,而是多项细节优化与系统工程协同的结果。首先是训练数据设计与混合策略,团队在保证单模态数据容量与质量的基础上进行了有针对性的跨模态对齐训练,使得模型在学习通用表示的同时保留各模态的专长。其次是专家网络(Mixture of Experts, MoE)的合理调度,通过动态路由机制将计算资源聚焦于当前任务相关的专家子网络,从而在参数量与计算效率之间取得平衡。再次是推理与部署优化,例如语音合成端到端流水线的模块化设计、低延迟解码器与多码本并行策略,确保模型不仅在实验室测评中领先,也能满足生产环境的实时性与稳定性要求。在应用场景层面,Qwen3-Omni的能力为多个产业带来直接价值。在线教育与无障碍服务可以借助准确的音频描述与多语种转写提升内容可达性。
媒体与娱乐领域能够在视频制作、自动配音与跨语种字幕生成上节省大量人工成本。客户服务与智能助手通过统一多模态理解与生成能力,实现更自然的语音交互、视觉问题识别与跨模态对话流程。在科研与内容创作中,Qwen3-Omni也为多模态数据分析、跨媒体检索与自动摘要生成提供了一体化工具链。尽管Qwen3-Omni展现出显著优势,仍需关注若干局限与风险。首先,多模态统一模型在大规模训练与推理中依然面临巨大的计算资源消耗,实际部署成本不容忽视。其次,跨模态模型存在潜在的幻觉风险,即在信息稀缺或相互冲突时生成不准确的描述或结论。
团队为此通过Thinking模块与更严格的训练信号来降低幻觉概率,但在极端场景下仍需结合外部检索与校验机制。再次是伦理与安全问题,模型在生成语音、图像描述或敏感内容时需要配合策略性过滤与合规审查,避免滥用或侵犯隐私。关于模型获取与许可,Qwen3-Omni-30B-A3B、Qwen3-Omni-30B-A3B-Thinking与Qwen3-Omni-30B-A3B-Captioner被公开发布并采用Apache 2.0许可证。这意味着研究者与开发者可以在遵守许可证条款的前提下访问与复现模型,从而推动社区在多模态研究与产业化应用方面的协同创新。开源发布也为可解释性、安全性与性能复核提供了基础,利于推动整个生态的透明化发展。展望未来,Qwen3-Omni所代表的方向可能引发一系列新的研究与产品实践。
一个重要方向是更细粒度的模态自主性与交互控制,使得模型在多模态融合时能够根据任务需求动态选择信息来源与推理深度,从而在效率与准确性间取得更优平衡。另一个方向是更强的因果推理与长期记忆能力,使模型在跨媒介的长期上下文中保持连贯性与事实性。此外,进一步压缩推理时的内存与计算开销、优化模型在边缘设备上的部署,将推动多模态AI在移动终端与嵌入式场景的落地。对企业与研究机构而言,Qwen3-Omni既是技术参考也提供了实践路径。企业在采纳多模态统一模型时,应重点评估数据隐私、合规性与推理成本,合理选择在线或离线部署策略。研究机构可以在Qwen3-Omni开源版本基础上开展可解释性分析、鲁棒性评估与对抗测试,进一步提升模型在真实世界复杂场景中的可靠性。
总结来看,Qwen3-Omni以其Thinker-Talker MoE架构、多码本流式语音合成和广泛的多语言支持,展示了多模态AI从能力折中走向全面领先的可行路径。开源释放的30B系列模型为社区提供了宝贵资源,加速从学术验证到工程落地的转化。尽管仍面临计算成本、幻觉风险与伦理挑战,Qwen3-Omni代表的技术路线明确推动了多模态AI向更实用、更实时、更通用的方向发展。对于开发者、产品经理与研究者而言,理解其架构设计与工程优化点,将有助于在未来的多模态产品与研究中更有效地应用与拓展这一新一代能力平台。 。