矩阵乘法是深度学习与科学计算中的核心计算模式,尤其是单精度浮点(FP32)乘加运算在神经网络推理与训练中无处不在。尽管主流数值库如 OpenBLAS、MKL 或 BLIS 已提供了高度优化的实现,但理解背后的原理并掌握在现代多核 x86-64 处理器上进行从零实现与调优的技巧,对工程师优化专用工作负载或跨平台移植具有重要价值。本文围绕 SGEMM(单精度通用矩阵乘法)展开,介绍如何在不依赖汇编的前提下,通过纯 C + SIMD intrinsics(如 AVX2 与 FMA3)在多核 CPU 上获得高效实现,并讨论常见的性能陷阱与调优要点。 要在多核处理器上实现高性能矩阵乘法,必须同时考虑指令级并行、寄存器利用、缓存层次与内存带宽。理想情况下,运算应尽可能在寄存器与 L1 缓存中完成,最大限度减少从 DRAM 的访问。现代 x86-64 CPU 提供 256 位 YMM 寄存器(AVX2)与融合乘加指令(FMA3),单条 VFMADD231PS 指令即可对 8 个浮点数执行乘加操作,显著提升每周期浮点吞吐量。
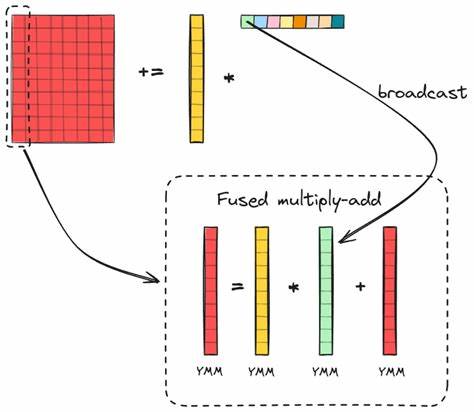
结合指令吞吐量与向量长度,可以估算单线程峰值 FLOPS,从而为后续优化提供参考上限。不过理论峰值往往受限于内存访问与并行效率,因此工程目标是尽可能接近该上限。 实现思路的核心是将大矩阵分解为若干小块,使用一个高效的微内核(micro-kernel)在寄存器级别完成小块的计算。微内核负责计算 C 的 m_R×n_R 子块,采用基于外积(outer product)的方式进行累加。外积策略在每次迭代从 A 载入一列(或若干列),从 B 载入一行(或若干行),对寄存器中的累加器执行 Rank-1 更新,从而在 K 维上逐步累积结果。与逐元素点乘相比,外积能最大化寄存器复用,减少内存带宽压力。
微内核设计需要在寄存器数量、向量长度与内核尺寸之间权衡。典型的 AVX2 环境下,YMM 寄存器数有限(例如 16 个),每个寄存器存放 8 个 float,微内核要同时保存累加器、来自 A 的列向量(可能分多寄存器保存)与用于广播 B 的标量向量。选择 m_R 与 n_R 时应确保 m_R 为向量长度的整数倍,以便整齐地映射到 YMM 寄存器,并满足寄存器数约束。不同微架构对最佳配置有所不同,非方形的内核(例如 m_R=16, n_R=6)在实践中常常比 8×8 更优,因为它更好地利用寄存器并减少指令开销。 在微内核内部,关键是使用 _mm256_loadu_ps、_mm256_broadcast_ss 与 _mm256_fmadd_ps 等 intrinsics 实现高效内循环。对每个 p(从 0 到 K-1)执行两次 16 元素的加载以获得列向量(分成两个 YMM),对 B 的每个列元素进行广播,再用 FMA 更新每一列的累加器。
循环展开与显式的寄存器命名可以帮助编译器避免寄存器溢出与不必要的内存溢出,提升生成代码的质量。使用编译后的汇编查看 vfmadd231ps 等指令是否被正确产生,是验证实现是否高效的简便手段。 实际矩阵尺寸通常不是 m_R 与 n_R 的整数倍,因此填充与边缘处理必不可少。对于 n 方向较短的余量,直接在存储阶段限制列数即可;而对于 m 不足的情况,由于 _mm256_storeu_ps 按 8 元素一次性写入更高效,常见做法是将不足的 A 块复制到局部缓冲区并用零填充,然后传入微内核计算,这样核心循环无需为边界条件引入分支与掩码开销。对于最终写回 C 的边界,可以使用 _mm256_maskstore_ps 结合 mask 向量实现有选择性的写回,而 mask 的生成可以通过预先准备的字节数组并用向量指令 cvtepi8_epi32 高效扩展得到,避免复杂的位运算分支。 缓存分块是应对多级缓存体系的另一关键。
将矩阵分为适合 L3、L2、L1 尺寸的块,可以显著降低 DRAM 访问频次。通常将 N 方向分为 nc、K 方向分为 kc、M 方向分为 mc(与微内核的 MR、NR 对应),并用打包(packing)将位于连续访问顺序的数据复制到缓冲区以保证访问模式友好。在高效实现中,B 面的块按行优先打包以利于在微内核中按行广播;A 面的块按列优先打包以利于列向量连续读取。打包阶段虽然会引入额外内存拷贝,但通过提高后续计算阶段的缓存命中率通常能带来净性能收益。 合理选择 kc、mc、nc 需要结合目标 CPU 的缓存大小。理论上让 kc×nc 填满 L3,mc×kc 填满 L2,kc×n_R 填满 L1 是起点,但实际最佳值往往是经验性的,需要基准测试。
通常适当放大这些参数以增加批量复用会更好。同时也要考虑线程数与块分割的关系,保证并行时每个线程有足够的独立块可处理,从而避免线程饥饿。在许多实现中,nc 与 mc 的选取会与线程数相乘来确保负载平衡,例如将 mc 设为 m_R×线程数×常数,确保打包与计算阶段均能被并行化。 多线程并行化既要并行化算术核,也要并行化打包阶段以避免串行瓶颈。常用方法是使用 OpenMP 在内层循环上并行化,例如在 jr 与 ir 等微内核级循环上使用 collapse(2) 使线程处理多个微块,或者并行化打包函数的外层循环以将打包开销分散到多个线程上。对于核心数较多的处理器,可能需要利用更细粒度的并行或者层次化并行策略。
要注意的是并行化时需要关注内存访问的亲和性与 NUMA 拓扑,使用 numactl 或线程亲和性设置(如 sched_setaffinity 或 OMP_PROC_BIND)可以避免跨节点内存访问带来的性能下降。 内存带宽与缓存一致性问题也会影响性能。大块并行写入可能引发伪共享,写入 C 的不同线程应尽量避免写入同一缓存行。打包缓冲区建议按 64 字节或更大对齐,堆栈局部大数组容易导致栈溢出或性能问题,建议使用静态或堆分配且对齐的缓冲区。预取(prefetch)指令在某些情况下有帮助,但现代 CPU 的硬件预取通常足够智能,过度手工插入 prefetch 可能适得其反,需通过性能分析工具验证效果。 编译器与指令集选择也很重要。
AVX-512 能带来更高的向量宽度与吞吐,但并非所有平台都支持。为了提高可移植性与对更广硬件的兼容性,可以选择 AVX2 + FMA3 路径,同时在编译时通过 -march=native 与 -mno-avx512f 等选项明确指令集。GCC 与 Clang 的优化水平差异会影响最终性能,使用 -O3 并结合具体微架构的 target 参数能让编译器发掘更多指令优化。即使使用纯 C 和 intrinsics,也应经常查看生成的汇编确认关键指令(如 vfmadd231ps、vmovaps、vbroadcastss)被正确生成。 基准测试设计必须谨慎以确保结果可信。建议在尽量空闲的环境下运行测试,固定线程数与频率,关闭不必要的后台服务,并设置合适的 NUMA 策略。
用中位数而非均值来汇总多次实验结果可以减少波动带来的误导。测量 FLOPS 时要基于准确的 2MNK 计算,并除以执行时间。对比 OpenBLAS 或 MKL 时应确保它们被以与你实现相同的指令集和线程策略编译与运行,例如在 Zen4/Zen5 上指定 TARGET=ZEN 避免 AVX-512 代码路径。 微观优化包含显式展开寄存器变量以避免数组访问开销,减少寄存器溢出,使用专门的掩码加载/存储处理边界,利用已对齐的数据以避免 unaligned loads 的性能损失等。生成掩码时直接用静态字节表并通过向量扩展生成 __m256i 可比序贯位移乘法更高效。内核的循环展开、将经常访问的指针保存在寄存器而非内存、以及尽量使用局部常量都能小幅累积成显著收益。
在可移植性与可维护性之权衡中,纯 C + intrinsics 的实现比汇编代码更易移植与理解,但在特定微架构上仍可能比手工汇编略逊一筹。另一方面,选择放弃 AVX-512 可覆盖更多旧硬件并减少实现复杂度。对于需要极致性能的产品,通常采用混合策略:在运行时检测 CPU 能力并选择不同实现(AVX2、AVX-512、或基于平台优化的 BLAS)是较为稳妥的做法。 最后,性能调优是一门工程与艺术的结合。建议采用系统化的性能验证流程:先构建正确的基线(简单的数值正确性与 naive 实现),逐步引入微内核、打包、缓存分块与并行化,每一步都用精确的基准验证收益。使用 perf、likwid、VTune 或 Linux 的 perf_events 可帮助定位缓存未命中、分支预测失误与内存带宽瓶颈。
重视线程绑定、NUMA 与内存对齐,避免伪共享与不必要的同步。根据不同微架构反复调整 MR、NR、MC、KC、NC 等超参数,记录最佳配置以支持生产部署。 掌握以上原理与实践后,即可在现代多核处理器上构建既高效又相对可维护的矩阵乘法实现。对于希望进一步深入的读者,推荐研读 GotoBLAS 与 BLIS 的设计论文,研究 OpenBLAS 等开源实现的打包与内核策略,结合实际硬件基准不断迭代优化。通过系统性的测试与逐步优化,可以在保证可移植性的前提下,将单精度矩阵乘法性能逼近专业 BLAS 库,满足许多深度学习推理与科学计算的高性能需求。 。









