近年来,大语言模型(Large Language Models,LLMs)已成为人工智能领域的重要支柱,广泛应用于自然语言处理、文本生成、机器翻译等多个领域。传统的自回归模型(Autoregressive Models,ARMs)凭借其较高的生成效率和稳定表现长期占据主导地位。然而,随着研究的深入和技术的演进,基于扩散过程的语言模型(Diffusion Large Language Models,dLLMs)逐渐崭露头角,展示了其在文本生成质量和多样性方面的显著优势。尽管dLLMs在生成策略上独树一帜,通过迭代去噪来完成文本生成,但其高昂的推理延迟成为限制其广泛应用的关键瓶颈。当前,大部分针对ARMs的加速技术并不适用dLLMs,尤其是传统的键值缓存机制与dLLMs的双向注意力机制存在兼容性问题。针对这一挑战,DLLM-Cache应运而生,提出了一种训练无关的自适应缓存框架,极大地提升了扩散式语言模型的推理速度,同时保障了模型输出的质量。
DLLM-Cache的核心创新在于其对dLLM推理过程的深入洞察。dLLM在生成文本时通常包含一个固定不变的提示(Prompt)和一个部分动态变化的响应(Response)。在每一个去噪步骤中,大部分生成的令牌内容保持稳定,仅小部分令牌发生改变。基于这一观察,DLLM-Cache设计了长周期的提示缓存策略结合基于特征相似度的部分响应更新机制,允许模型高效重用之前计算的中间结果,显著减少重复计算的开销。该缓存方案无需额外训练,具备极强的通用性,可广泛适配不同的dLLM架构。深入分析DLLM-Cache的工作机制可以发现,其首先对输入的固定提示进行缓存,一旦提示被存储,未来的推理步骤便可以避免重新计算该部分内容。
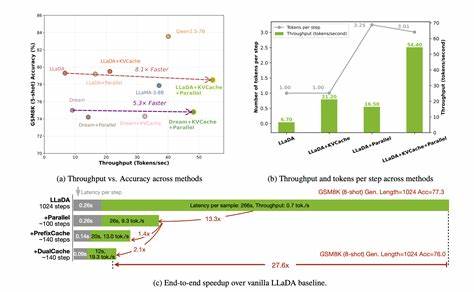
针对响应内容,DLLM-Cache通过计算当前与前一时刻中间特征的相似度,精确定位发生变化的令牌范围,并仅对该范围进行重新推理计算。这种部分更新策略大幅度减少了计算量,优化了内存使用,提升了推理效率。在实际应用测试中,以LLaDA 8B和Dream 7B为代表的扩散式大语言模型通过DLLM-Cache实现了最高9.1倍的推理加速,且模型生成的文本质量与标准推理方法保持高度一致。这一成果不仅缩小了dLLM与传统ARMs在推理延迟上的差距,也为扩散式语言模型的实际落地提供了强有力的技术支撑。此外,DLLM-Cache框架的设计理念和实现方式具有良好的扩展性和灵活性。它可以结合更多潜在的优化技术,如混合精度计算、并行推理增速等,进一步推动dLLM推理效率的极限突破。
随着智能应用需求的持续增长,对模型实时推理性能的要求也日渐严格,DLLM-Cache为科研人员和工程师提供了一条切实可行的提升路径。未来,扩散式大语言模型有望通过DLLM-Cache这样的技术,获得更广泛的应用场景支持,从交互式对话到复杂文本生成,再到个性化内容推荐,均能实现更快速响应和高质量输出。同时,随着缓存机制和模型结构的不断迭代优化,扩散式模型在效率与表现上的平衡将变得更加成熟与细致,推动人工智能语言理解与生成技术整体迈向新高度。总的来说,DLLM-Cache凭借其自主创新的自适应缓存方案,成功破解了扩散式大语言模型推理瓶颈,为该领域带来了不可忽视的性能提升和实践价值。它不仅丰富了大语言模型的加速技术体系,也为后续研究和应用部署树立了重要标杆。展望未来,DLLM-Cache有望成为推动下一代高效智能语言模型发展的重要引擎,助力实现更加迅速、智能和精准的自然语言处理服务。
。