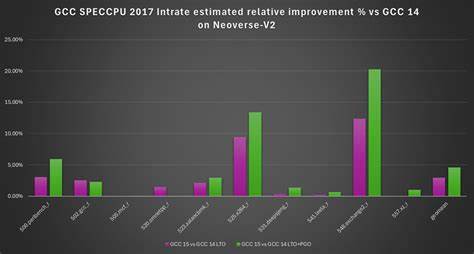
随着Arm架构在服务器、高性能计算及移动设备领域的不断普及,针对AArch64的编译器优化已成为提升整体系统性能的关键环节。GNU编译器集合(GCC)作为业内重要的开源编译器项目,其版本迭代对Arm生态的影响深远。GCC 15版本作为近年来的重大更新,以持续改进为核心,带来了针对AArch64架构的多项优化,显著增强了代码生成效率和执行性能,为开发者提供了更高效的工具支持。首先,GCC 15在向量化方面做出了重要突破。GCC在之前版本中实现了统一的循环向量化器——仅保留了对循环感知的SLP(Superword Level Parallelism)向量化器的支持,简化了维护和拓展的难度。该版本进一步完善了对早期循环退出(early break)的向量化支持,解决了GCC 14中存在的代码冗余和活跃变量处理不足的问题,生成了更加简洁高效的循环体。
这一改进对控制流复杂的循环,尤其是在高性能计算领域的应用表现出巨大推动力,例如GROMACS等科学计算软件的性能因此得到提升。值得注意的是,GCC 15引入了针对对齐问题的剥离(peeling)技术,放宽了此前对静态已知缓冲区大小的限制,显著提高基于Adv. SIMD和固定长度SVE向量长度的循环向量化覆盖度,同时为下一代GCC 16版本中基于故障加载的泛型SVE向量化奠定基础。此外,对于包含预取指令(__builtin_prefetch)的循环,GCC 15能智能地在向量化过程中忽略这些提示,避免早期版本因内存访问副作用而放弃向量化的情况,提升了编译器对工程实际代码的兼容与优化能力。GCC 15还新增了SVE2.1指令集中两项点积(dot product)操作的自动向量化支持,通过利用SVE的两路无符号点积指令udot,显著加快了数字信号处理相关的计算性能。同时,该版本还扩展了对SME(Scalable Matrix Extension)功能的自动向量化,允许开发者通过特定属性启用流模式(streaming mode),简化矩阵乘法等大规模计算的优化过程。在数学函数自动向量化方面,GCC 15继续增强对glibc libmvec库的支持,进一步扩大了数学函数和用户自定义函数的向量化覆盖,使得科学计算和工程计算中的函数调用性能优化成为可能。
另一项重大的创新是支持饱和算术指令。GCC 15能够自动识别并调用硬件级的饱和指令,不论是标量还是向量形式,这对信号处理和图像处理等领域非常有价值。为了避免不必要的性能损失,编译器还引入了成本模型,优先根据参数寄存器(GPR)和浮点寄存器(FPR)使用情况决定是否采用饱和指令或替代序列。另外,GCC 15改进了人口计数(popcount)函数的向量化策略,充分利用Adv. SIMD及SVE的特性,甚至结合点积指令优化,使得在不同数据类型和向量长度下都能生成高效的指令序列。ARM Cortex-MVE(M-Profile Vector Extension)在32位Arm中的尾部预测(tail predication)也受益于GCC 15的支持,这一技术避免了传统向量循环中须要的末尾标量循环处理,大幅提高了代码简洁性和执行效率。FP8浮点数格式作为Armv9架构中的新成员,在GCC 15中获得正式支持。
该标准定义了8位浮点数的两种子格式(E4M3和E5M2),允许在低精度计算场景中节省内存和功耗。GCC 15通过intrinsics接口实现FP8指令的调用,并引入了专门的寄存器活跃度追踪以优化FPMR寄存器的切换,提升了FP8计算的代码生成质量。原子操作库libatomic在GCC 15中新增对RCPC3指令集的支持,该指令集自Armv8.2-A向上版本引入,增强了负载释放对的原子性,适用于多核心同步操作,配合LSE2(Large System Extensions 2)功能可自动发挥硬件优势。除了指令级优化,GCC 15还更新了对Neoverse微架构的支持,包括Arm Cortex-A520AE、A720AE、A725、R82AE及Neoverse N3、V3与V3AE等型号,为这些新兴核心提供了定制化的调度和成本模型调整,帮助释放其硬件潜能。缓存策略方面,GCC 15将默认的一级数据缓存行大小调整为64字节,符合当下主流Armv9-A及Neoverse核心设计,减少多线程环境下的内存压力和无效数据传输。浮点乘加链路(FMA)代码生成也实现了流水线支持,根据核心可并行执行的FMA数量,编译器能够智能重组表达式以填满流水线,充分利用计算单元转发,从而提升数值计算密集型应用的吞吐量。
指令融合方面,Neoverse核心特有的CMP(比较)与CSEL(条件选择)融合得到了GCC 15引入,编译器会保持这两条指令的顺序和排列,有助于减少执行周期和资源占用。体系结构支持方面,GCC 15增加了对Armv9.5-A新架构的支持,同时也独立实现了众多细粒度的特征支持,如CPA(Continuous Packed Addends)、FAMINMAX(Fused Min/Max)、FCMA(Fused Multiply-Add for Compressed formats)、FP8及FP8相关的点积与FMA扩展等,为开发者提供了更多灵活调优的选项。标准C++语言层面,GCC 15将SVE向量类型的操作符重载加入支持,允许程序员使用自然的算术运算符对SVE数据类型进行操作,降低了编写和维护底层向量化代码的难度,提升开发效率。OpenMP并行计算对SVE的协同支持也加强了,支持parallel sections、for循环及lastprivate等语义,使得多线程向量化更加顺畅。循环中归纳变量优化(IV opts)经过改进,针对符号与无符号表达式的统一识别以及处理,在提高代码生成效率的同时,特别优化了Fortran等语言的地址计算模式,避免不必要的复杂寻址,进一步增强了跨语言的兼容性和性能。值得一提的是,ILP32 ABI支持在GCC 15中正式进入弃用阶段,提醒开发者提前调整,以避免未来版本中的兼容性问题。
为应对异构多核系统的复杂情况,-mcpu=native选项也得到改进,如在检测未知大.LITTLE芯片时,GCC能够自动提炼多核共享的硬件特征,确保生成代码的现代化和优化性。C++标准库libstdc++得到了引人注目的性能提升,诸如std::find循环不再手工展开,改用GLIBC的高效memchr且加入向量化支持。此外,修正了从GCC 12版本以来影响哈希映射查找性能的内联问题,重新启用了相关函数的内联,从内部概率分布和分支预测层面优化,提高命中率和循环效率。默认针对Cortex-A53的错误修正措施得以在GCC 15中智能关闭,避免引入不必要的性能损耗,特别是在Neoverse和SVE核心中展现明显优势。立即数生成优化巧妙利用了SVE的广泛立即数范围,扩展了Adv. SIMD指令的灵活性,生成更紧凑高效的指令序列。伴随核心零值初始化策略更新,标准化所有零寄存器生成为统一模式,提升指令共享率和代码密度。
复杂的向量排列(permute)操作也有了多项针对性优化,有效减少寄存器间复制和多余指令,改进早期寄存器分配,避免不必要的数据移动,最终带来更高执行效率。新引入的晚期合并(late combine)编译优化在指令分解和寄存器分配前后运行两次,重点挖掘可合并表达式,提高复杂寻址模式利用率,适配现代Arm核心对复杂寻址的低成本支持。针对编译时间,GCC 15对早期调度机制进行了裁剪,默认关闭低于-O3的早期指令调度,大幅缩减编译时长,同时带来微小代码尺寸减少,尤其适合大规模项目构建。SVE内置函数也得到了大量常量表达式优化,消除冗余计算,提升编译器前后端的协同效果。针对位操作,如计数尾零(CTZ)和向量旋转,GCC 15采用更高效的指令组合,利用如RBIT、REV及XAR指令,替代先前基于移位的方案,明显降低指令延迟和执行周期。循环中的CRC检测新增自动识别硬件加速指令的能力,包括位反转和正向CRC计算,为数据完整性校验提供高性能方案。
针对数学函数调用中的性能瓶颈,GCC 15借助SVE指令FSCALE及ASRD扩展,避免代价昂贵的库函数调用,特别是对于ldexp、powif和powof2等操作,显著降低开销。大型程序中调用关系的代码局部性调优也得到改进,通过PGO(Profile Guided Optimization,性能引导优化)或静态预测,GCC 15调整函数布局,缩短调用距离,提升I-Cache利用率和整体执行效率。新版本还受益于glibc中malloc的改进,通过分离tcache快速路径和延迟初始化机制,提高多线程内存分配性能,尤其是在Neoverse V2平台上表现出显著提升。安全性方面,GCC 15首次引入受保护控制栈(Guarded Control Stack,GCS)支持,结合Linux 6.13内核及Binutils 2.44等工具链,利用硬件阴影栈防护返回地址篡改,提高运行时安全性。GCS的集成不仅无需用户代码改动,还支持调试和性能分析工具更为准确和高效的调用栈追踪,推动Arm生态安全性迈上新台阶。综上所述,GCC 15在AArch64架构上呈现了一场全面而深刻的优化升级,从底层指令生成到高层语言支持,再到安全防护和工具链配套,都体现出对现代Arm生态需求的精准把控和积极响应。
未来,随着GCC 16及其后续版本的持续投入,结合新硬件特性与生态应用,我们有望见证更高效、更安全、更智能的Arm软件开发时代。